大数据服务器配置要求
 社区干货
社区干货
火山引擎——大数据智能平台的构建策略与步骤|社区征文
首先是数据系统的建设,数据系统是基础。从确定要进行哪些方面的数据收集开始,需要把收集到的数据进行清洗、筛选、格式转换、存入系统中,并且按照技术平台的要求,投入人力、设备等进行大数据系统的搭建。其次是数据... 对应到系统建设方面也就是大致下面几个:● 数据收集系统:确定数据源,数据格式,数据传输方法,数据清洗工具等。● 搭建存储集群:确定存储规模、服务器配置和数量、网络规划及建设、安装和调试集群、确定存储方式...
海量笔记@在云上,如何搭建属于自己的全文搜索引擎 Web应用-个人站点 | 社区征文
**阿里云服务器连接**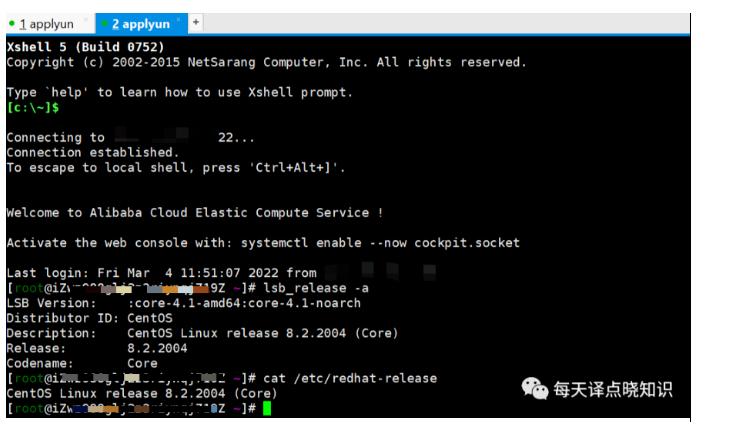 **附注:** 从上述可知,当前云主机的发行版本为CentOS,当然,若是对于系统访问并发高,业务数据量非常之大的话,除了系统前后台代码本身质量优化之外,服务器配置(物理机or虚拟机or云主机)还可选择更高配些! Ok,now,有了这些前提条件,接下来开始**安装部署**我们**译...
工业大数据分析与应用——知识总结 | 社区征文
智能地分配硬件资源来满足业务部门的不同需求 * 跨资源池动态平衡计算资源 * 基于预先设定的规则智能分配资源 * 对客户的优势 * 基于业务优先级分配资源 * 简化运行,大幅度提高系统管理员的生产率 * 动态添加硬件资源而避免在繁忙时段服务器的过载 * 动态硬件维护能力* **启用“即插即用”数据中心** * 原理 * 插入:接通新服务器电源。新服务器即加入群集。 * 使用:群集中所有的虚拟机会自动重...
三分钟了解大数据技术发展史|社区征文
这三篇论文影响了当今大数据生态,可以称得上大数据的基石,Doug cutting 大佬在基于谷歌的三篇论文开发出了 hadoop hdfs 分布式文件存储、MapReduce 计算框架,实际上从 hadoop 开源代码中窥见大数据并没有多么高深的技术难点,大部分实现都是基础的 java 编程,但是对业界的影响是非常深远的。那个时候大多数公司还是聚焦在单机上,如何尽可能提升单机的性能,需求更贵的服务器,谷歌通过把许多廉价的服务器通过分布式技术组成一个大的...
 特惠活动
特惠活动
 大数据服务器配置要求-优选内容
大数据服务器配置要求-优选内容
 大数据服务器配置要求-相关内容
大数据服务器配置要求-相关内容
配置 Flink 访问 CloudFS
前提条件开通大数据文件存储服务 CloudFS 并创建文件存储,获取挂载信息。详细操作请参考创建文件存储系统。 完成 E-MapReduce 中的集群创建。具体操作,请参见 E-MapReduce 集群创建。 准备一个测试文件。 步骤一:配置 CloudFS 服务说明 集群所有节点都要修改如下配置。 连接 E-MapReduce 集群,连接方式如下: 使用本地终端 ssh 连接集群节点管理 master 的公网 ip。 使用同区域下的云服务器实例连接集群节点管理 master 的内网...
字节跳动云原生大数据平台运维管理实践
可能会涉及到多个依赖和配置管理。有强依赖,比如各种任务引擎对底层大数据存储的依赖;也有弱依赖,比如任务引擎对日志监控系统的依赖;甚至还有循环依赖,比如消息中间件可能需要采集日志,但日志采集本身又依赖消息中... **稳定性高**:运维管理对稳定性的要求很高,即使在发生故障的情况下,也要能够快速恢复,并且也需要对其他组件提供容灾管理的能力;- **可移植性强**: 运维管理模块的一个大目标就是支持整个云原生大数据产品的...
如何 Get 字节跳动同款云原生大数据平台
随着业务和数据的快速增长,云计算和大数据技术也得到了迅速发展,云原生化和智能化已成为一种趋势。在此背景下,字节跳动进行了一系列大数据架构 Serverless 化的探索与实践,并在 AI 智能化方向进行了研究,最终形成火... 随着图片和视频数据的爆炸式增长,人们对于多样化数据搜索的需求也越来越迫切。多模态搜索场景已经成为当前搜索领域的主要趋势。在这个背景下,本次演讲将重点介绍字节跳动在K-NN向量搜索领域的探索,并探讨如何在多模...
如何 Get 字节跳动同款云原生大数据平台
随着业务和数据的快速增长,云计算和大数据技术也得到了迅速发展,云原生化和智能化已成为一种趋势。在此背景下,字节跳动进行了一系列大数据架构 Serverless 化的探索与实践,并在 AI 智能化方向进行了研究,最终形成火... 随着图片和视频数据的爆炸式增长,人们对于多样化数据搜索的需求也越来越迫切。多模态搜索场景已经成为当前搜索领域的主要趋势。在这个背景下,本次演讲将重点介绍字节跳动在K-NN向量搜索领域的探索,并探讨如何在多模...
字节跳动云原生大数据平台运维管理实践
可能会涉及到多个依赖和配置管理。有强依赖,比如各种任务引擎对底层大数据存储的依赖;也有弱依赖,比如任务引擎对日志监控系统的依赖;甚至还有循环依赖,比如消息中间件可能需要采集日志,但日志采集本身又依赖消息中... 那么就要求它本身就不能有环境耦合的问题,并且所有的相关功能都需要支持插拔式设计,可以灵活的在不同环境提供一套完整的运维管理功能;* **环境感知弱** :向上层业务屏蔽由于环境差异带来的运维管理的差异性,保证上...
年终学习大礼包|云原生大数据知识地图
**大势所趋:云原生大数据**随着行业的快速发展和业务的高速迭代,数据量也呈爆炸式增长,传统的大数据架构在资源利用、高效运维、可观测性等方面存在诸多不足,已经越来越无法适应当下的发展需求。具... 云原生大数据平台的功能架构可以总结为“三大平台和一大支撑体系”。三大平台分别是 **平台服务层、核心引擎层**和 **资源调度层** **。*** 平台服务层由开源组件插件化集成,支持灵活配置选用;* 核心引擎层...
如何 Get 字节跳动同款云原生大数据平台
随着业务和数据的快速增长,云计算和大数据技术也得到了迅速发展,云原生化和智能化已成为一种趋势。在此背景下,字节跳动进行了一系列大数据架构 Serverless 化的探索与实践,并在 AI 智能化方向进行了研究,最终形成火山引擎云原生大数据平台方案。 11月18日,在由上海白玉兰开源开放研究院、人工智能开源软件发展联盟联名主办的 **Data & AI Con Shanghai 2023** 大会上,将特别设立**云原生****大规模计算实践专场**。来自火山...
购买并使用云服务器实例
以最简单的方式搭建一台云服务器实例,包括购买、连接、应用部署以及释放等。 说明 如果您是首次使用云服务器,您也可以通过快速购买实例购买轻量级云服务器实例,此种方式无需手动输入或自定义参数配置,更加方便快捷... 系统盘将完整复制镜像的操作系统和应用数据。数据盘用于存储应用数据。 网络配置 私有网络 默认私有网络 如果没有创建私有网络,可以选择默认私有网络。 子网 默认子网 如果没有创建私有网络及子网,可以选择...
年终学习大礼包|云原生大数据知识地图
# 大势所趋:云原生大数据随着行业的快速发展和业务的高速迭代,数据量也呈爆炸式增长,传统的大数据架构在资源利用、高效运维、可观测性等方面存在诸多不足,已经越来越无法适应当下的发展需求。具体来讲,传统大数据... 云原生大数据平台的功能架构可以总结为“三大平台和一大支撑体系”。三大平台分别是**平台服务层、核心引擎层**和**资源调度层。**- 平台服务层由开源组件插件化集成,支持灵活配置选用;- 核心引擎层包括 Fl...
