otter同步到数据仓库
 社区干货
社区干货
ByteHouse MaterializedMySQL 增强优化
实现了基于 MySQL Binlog 机制的业务数据库实时同步功能。 这样不依赖其他数据同步工具,就能将 MySQL 整库数据实时同步到 ClickHouse,从而能基于 ClickHouse 构建实时数据仓库。 ByteHouse 是基于 ClickHouse 增强自研的云原生数据仓库,在社区版 ClickHouse 的 MaterializedMySQL 之上进行了功能增强,让数据同步更稳定,支持便捷地处理同步异常问题。# 社区版 MaterializedMySQL 简介ClickHouse 社区版通过 DDL 语...
只需五步,ByteHouse实现MaterializedMySQL能力增强
MaterializedMySQL数据库引擎,用于将MySQL中的表映射到ClickHouse中。ClickHouse服务作为MySQL副本,读取Binlog并执行DDL和DML请求,实现了基于MySQL Binlog机制的业务数据库实时同步功能。**这样不依赖其他数据同步工具,就能将MySQL整库数据实时同步到ClickHouse,从而能基于ClickHouse构建实时数据仓库。** ByteHouse是基于ClickHouse增强自研的云原生数据仓库,在社区版ClickHouse的MaterializedMySQL之上进行了功能增...
「火山引擎」数据中台产品双月刊 VOL.04
**火山引擎数据中台产品双月刊**涵盖「大数据研发治理套件 DataLeap」「云原生数据仓库 ByteHouse」「湖仓一体分析服务 LAS」「云原生开源大数据平台 E-MapReduce」四款数据中台产品的功能迭代、重点功能介绍、平台... 让数据查询、访问迁移和模型设计更加便捷。- **【新增ByteHouse企业版功能】** - 在社区版本 MaterializeMySQL 库引擎的基础上支持了集群模式(Distributed_mode),支持将 MySQL 中的库同步到集群并自动分...
ByConity 技术详解之 ELT
谈到数据仓库, 一定离不开使用Extract-Transform-Load (ETL)或 Extract-Load-Transform (ELT)。 将来源不同、格式各异的数据提取到数据仓库中,并进行处理加工。传统的数据转换过程一般采用Extract-Transform-Load ... **整体易扩展**:导入和转换通常需要大量的资源,系统需要通过水平扩展的方式来满足数据量的快速增长。1. **可靠性和容错能力**:大量的job能有序调度;出现task偶然失败(OOM)、container失败时,能够拉起重试;能处...
 特惠活动
特惠活动
 otter同步到数据仓库-优选内容
otter同步到数据仓库-优选内容
 otter同步到数据仓库-相关内容
otter同步到数据仓库-相关内容
功能发布记录(2023年)
HBase 数据源支持火山引擎 HBase 数据库标品数据源配置; Doris 数据源新增支持离线读取 Doris 数据; 新增 VeDB 数据源配置,支持离线读取和写入 VeDB 数据; 新增火山引擎 TLS 数据源配置 实时整库、分库分表同步解... 仓库绑定。 创建项目支持绑定 EMR StarRocks 集群类型。 参数设置支持查看批式/流式关联任务。 资源组管理 项目管理 参数信息设置 2023/06/15序号 功能 功能描述 使用文档 1 华东2 DataLeap 服务部署 数据...
ELT in ByteHouse 实践与展望
格式各异的数据提取到数据仓库中,并进行处理加工。 传统的数据转换过程一般采用Extract-Transform-Load (ETL)来将业务数据转换为适合数仓的数据模型,然而,这依赖于独立于数仓外的ETL系统,因而维护成本较高。现在,以火山引擎ByteHouse为例的云原生数据仓库,凭借其强大的计算能力、可扩展性,开始全面支持Extract-Load-Transform (ELT)的能力,从而使用户免于维护多套异构系统。具体而言,用户可以将数据导入后,通过自定义的SQL...
工业大数据分析与应用——知识总结 | 社区征文
大数据产业链的4个环节 - 大数据生产与集聚 - 如交易数据、交互数据、传感数据。 - 大数据组织与管理 - 如开展分布式文件系统、分布式计算系统、数据库、数据仓储、MOLAP、HOLAP、数据转换工具、数据... 异构数据源**中的数据如关系数据、平面数据文件等,抽取到临时中间层后进行**清洗、转换、集成**,最后加载到**数据仓库或数据集市**中,成为联机分析处理、数据挖掘的基础;或者也可以把实时采集的数据作为流计算系统...
达梦@记一次国产数据库适配思考过程|社区征文
若是通过**Mysql或Oracle或其他数据库,文件等方式迁移导入**。这里记录一下迁移过程中遇到的问题,**在迁移的时候,报某些字段超长**。于是,查看了MySql中那些字段的类型及长度,都是varchar(50) 。这里应该是迁移有些... ```说明:这里的groupId坐标参数,可由使用者自行在nexus中upload创建声明,然后在pom.xml中引入相关坐标即可。扩展:若是需要从本地deploy到nexus或是先获取本地仓库.m2的包->nexus仓库的包->aliyun maven仓库的包...
干货 | 这样做,能快速构建企业级数据湖仓
自己做同步又会引入一致性的问题;* 对业务吸引不够:由于以上三点原因,Table Format 对业务的吸引力大打折扣。如何去解这些问题呢?现在业界已经有基于 Table Format 应用的经验、案例或者商业公司,比如 Data B... Codegen 和向量化都是从数据仓库,而不是 Hadoop 体系的产品中衍生出来。Codegen 是 Hyper 提出的技术,而向量化则是 MonetDB 提出的,所以计算引擎的精细化也是沿着数仓开辟的路子在走。Spark 等 Hadoop 体系均走...
功能发布记录(2024年)
StarRocks 3.X 数据源类型版本支持 Binary 字段类型; ByteHouse CDW 数据源优化网络配置,支持通过内网形式访问。 离线整库解决方案在目标配置时,支持源端表与目标表刷新配置,可自定义整库同步时单次拉取表的数量... 临时查询执行和数据开发任务调试支持选择是否开启任务成功\失败时的消息通知; 资源库支持EMR和通用(Shell/Python)引擎的资源类型进行跨引擎复制、华北地域资源来源新增制品仓库(SCM)形式; 调度时间变量参数支持分...
观点 | 数据分析引擎百花齐放,为什么要大力投入ClickHouse?
随着云计算等技术发展以及海量数据应用场景等出现,对数据仓库提出全新要求,高性能、实时性、云原生等成为数据仓库发展关键词,也因此演变出不同的数仓发展路径。> > > > > **在字节跳动十年发展历程中,各类业务... 和嵌套数据结构(Nested Data Structure);* 支持数据库异地复制部署。**3. 数据导入速度快**ClickHouse使用大规模并行计算框架,超高吞吐的实时写入能力,每秒在50-200M量级。ClickHouse采用类LSM Tre...
浅谈数仓建设及数据治理 | 社区征文
因此数据仓库会存在大量冗余的数据;不分层的话,如果源业务系统的业务规则发生变化将会影响整个数据清洗过程,工作量巨大。2. 通过数据分层管理可以简化数据清洗的过程,因为把原来一步的工作分到了多个步骤去完成,... 数据层具体实现>使用四张图说明每层的具体实现- **数据源层ODS** 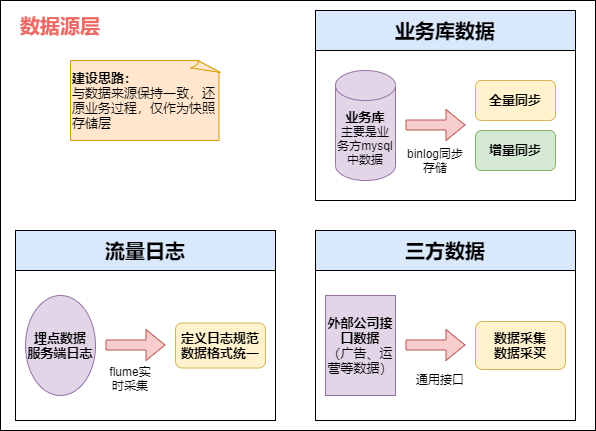数据源层主要将各个业务数据导入到大数据平台,作为业务数据的快...
2022 年每个开发者必知的云原生趋势 | 社区征文
数百万行代码全部放到一个仓库;对于差异需求,直接复制项目仓库单独开发,同时维护多个仓库代码。2. Dependencies-显示和隔离的**依赖**>Explicitly declare and isolate dependencies每个微服务都可以显式声明... 开发环境数据库没主从,产线配置了主从同步。这样在MySQL读写分离时,主从同步那几毫秒的延迟导致各种奇怪Bug,在开发环境也许永远都重现不出来。11. Logs-作为事件流的**日志**>Treat logs as event streams将微...
