数据仓库中ods层是什么意思
 社区干货
社区干货
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直接作为数仓的存储层,优点是不关心数据的格... 但是Kafka本身不是一个数据库,不支持SQL查询,也不支持数据的索引和聚合,因此在数据分析方面的能力有限。另外Kafka是一个基于事件的系统,不同于传统的基于事实表和维度表的数据仓库建模方式,因此需要对数据的建模和...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
### 1. 开篇2023年即将过去,又到了一年一度的技术总结时刻,在这一年,参与了多个大数据项目的开发建设工作,也参与了几个数仓项目的治理优化工作,在这么多的项目中,让我印象比较深刻的就是在使用Spark引擎执行任务出... 需要全表数据参与,后面经过调研,发现Iceberg是支持行级更新,并且和Spark结合的比较好,经过测试之后发现没有问题,后面数仓整体就迁到了Iceberg中。这次任务的执行语句描述:将ODS层的表按照主键去重后插入到DWD层中...
DataLeap数据仓库流程最佳实践
应用数据层。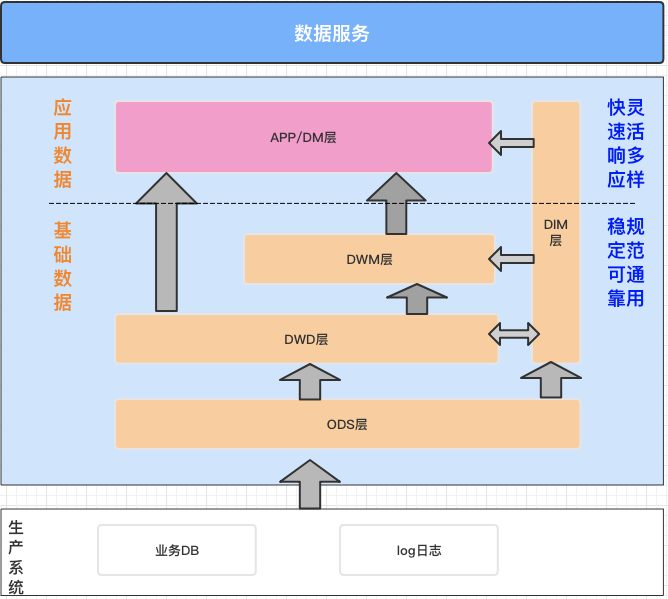本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表:![图片]...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效和精准的决策**第一个视角是从业务视角出发,我们可以提炼为三个字为**管**,**产**,**运**1、管是管理,即让管理层进行科学决策【不再是屁股决定脑袋的决策】2、产是产品,即让产品流程优化,快速迭代【不再自嗨...
 特惠活动
特惠活动
 数据仓库中ods层是什么意思-优选内容
数据仓库中ods层是什么意思-优选内容
 数据仓库中ods层是什么意思-相关内容
数据仓库中ods层是什么意思-相关内容
一种在数据量比较大、字段变化频繁场景下的大数据架构设计方案|社区征文
从源系统同步过来的数据落到ODS层,但是要注意采集数据时需要能捕获到源系统表结构的变更,可以采用Flink CDC等。ODS层的数据落到Kakfa中,设置一个较长的保存周期。kafka直接作为数仓的存储层,优点是不关心数据的格... 但是Kafka本身不是一个数据库,不支持SQL查询,也不支持数据的索引和聚合,因此在数据分析方面的能力有限。另外Kafka是一个基于事件的系统,不同于传统的基于事实表和维度表的数据仓库建模方式,因此需要对数据的建模和...
在大数据量中 Spark 数据倾斜问题定位排查及解决|社区征文
### 1. 开篇2023年即将过去,又到了一年一度的技术总结时刻,在这一年,参与了多个大数据项目的开发建设工作,也参与了几个数仓项目的治理优化工作,在这么多的项目中,让我印象比较深刻的就是在使用Spark引擎执行任务出... 需要全表数据参与,后面经过调研,发现Iceberg是支持行级更新,并且和Spark结合的比较好,经过测试之后发现没有问题,后面数仓整体就迁到了Iceberg中。这次任务的执行语句描述:将ODS层的表按照主键去重后插入到DWD层中...
DataLeap数据仓库流程最佳实践
应用数据层。本样例中,我们的数据仓库建设思路是:* ODS(从生产系统采集原始数据,并将原始数据集成冗余宽表)* DWD(对ODS冗余表数据进行轻度过滤处理)* DWM (基于DWD表与业务需求,轻度聚合最近三天的数据)* APP (基于DWD或DWM,输出具体报表信息)在“数据地图”中创建数据仓库中要使用到的表:![图片]...
数仓黄金价值圈: 为什么、是什么、怎么做|社区征文
今天给大家一起分享下有着悠久历史的数据仓库的一些思考由三部分组成为什么,搭建数据仓库是什么,数据仓库定义怎么做,如何搭建数仓# 一:为什么,搭建数据仓库最终目标:**数据驱动资源优化配置,即科学、高效和精准的决策**第一个视角是从业务视角出发,我们可以提炼为三个字为**管**,**产**,**运**1、管是管理,即让管理层进行科学决策【不再是屁股决定脑袋的决策】2、产是产品,即让产品流程优化,快速迭代【不再自嗨...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。## 服务层服务层包括了所有与用户交互的内容,包括用户管理、... Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对...
创建数据源管理
说明 创建数据源是为了数据集成做准备,关于创建的更多细节,请参见链接背景:在项目下管理ODS、DIM等原始数据信息,需要将源端Mysql数据同步到对应的ODS/DIM目标端表,为后续DWD层数据加工做准备注意:数据同步使用的数据源,需保证资源组和数据源是在一个vpc网络环境中,首次使用需添加数据集成资源组并绑定VPC网络。 1)使用demo02 在控制台的左侧导航中,点击【项目管理】->【配置信息】2)进入数据源管理,点击新建数据源3)连通性测试,...
创建专题设置
“数据专题”以业务视角出发,将服务于同一业务场景的表归纳整理,形成数据仓库,方便使用者查询及管理。以营销场景为例,可以按照商品中心、会员中心等方向,形成对应数仓。PS:专题中,涉及到产品线、业务域、主题、层级... 层级 添加库:单击“添加库”按钮,以此数据las schema库,添加 ods、dim、dwd、dwm 库。 点击确认选择,再点击确认后保存成功 可按需编辑专题调整等操作,同时支持目录刷新
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(上)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** **近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。** 白皮书简述了 ByteHouse 基于 ClickHous... 实现存储层与计算层的分离,独立扩缩容。- 新一代 MPP 架构:结合 Shared-nothing 的计算层以及 Shared-everything 的存储层,有效避免了传统 MPP 架构中的 Re-sharding 问题,同时保留了 MPP 并行处理能力。- 数...
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0 (Ⅵ)
> 更多技术交流、求职机会,欢迎关注**字节跳动数据平台微信公众号,回复【1】进入官方交流群** 近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。 **以下为 ByteHouse 技术白皮书【核心技术解析——元数据】版块摘录...
