ByteHouse 企业版
ByteHouse 企业版



文档指南

请输入


- 文档首页
 ByteHouse 企业版开发参考SQL 参考表引擎MergeTreeDistributed
ByteHouse 企业版开发参考SQL 参考表引擎MergeTreeDistributed

Distributed
使用 HaMergeTree 表引擎时,ByteHouse 的数据分片需要结合分布式表引擎(Distributed)一起使用。
Distributed 表引擎本身不存储任何数据,它能够作为分布式表的一层代理,在集群内部自动展开数据写入、分发、查询、路由等工作。
架构与原理
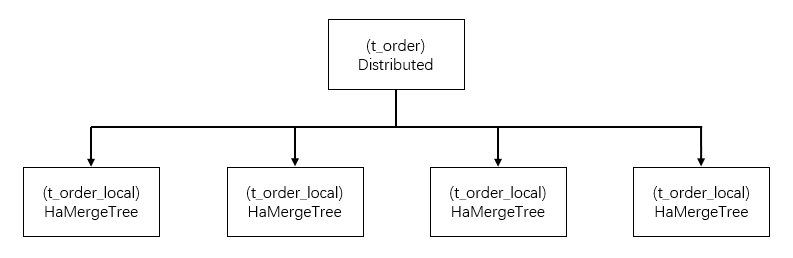
从上图可以看出一张表分成了两部分:
- 本地表:通常以
_local后缀进行命名。本地表是承接数据的载体,可以使用 非 Distributed 的任意表引擎,我们建议使用 HaMergeTree,或 HaUniqueMergeTree - 分布式表:通常以业务表直接命名,分布式表只能使用 Distributed 表引擎,他们与本地表形成一对多的映射关系,以后通过分布式表代理操作多张本地表。
而为了让整个集群的每一个节点都可查,也需要将分布式表建到每个节点上。因此,对于一张业务表,需要在每个节点上都分别创建一张分布式表,和一张本地表。架构如下图: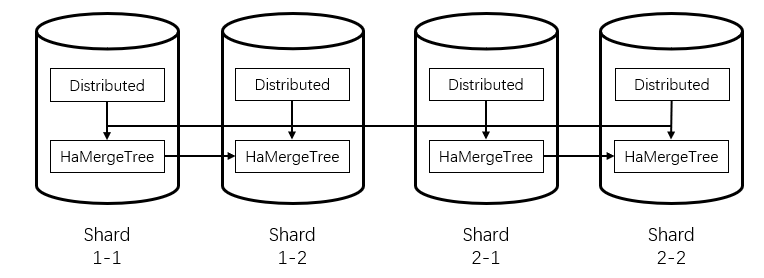
分布式表的查询
当 Distributed 表执行查询操作的时候,会依次查询每个分片的数据,然后再汇总返回。
分布式表的写入
当对 Distributed 表的执行写入时,会先写入本地,再根据分片键(Shard Key)计算数据应该写入哪些节点,建立远程链接,再分发到这些节点。
但这样做有一些缺点:
- Part 同步问题:分布式表接收到数据后会将数据拆分成多个 parts,并转发数据到其它服务器,会引起服务器间网络流量增加、服务器merge的工作量增加,导致写入速度变慢,并且增加了 Too many parts 的可能性。
- 数据的一致性问题:先在分布式表所在的机器进行落盘, 然后异步的发送到本地表所在机器进行存储,中间没有一致性的校验,而且在分布式表所在机器时如果机器出现宕机, 会存在数据丢失风险。
- 数据写入默认是异步的,短时间内可能造成不一致。
因此,ByteHouse 的读写建议为:插入 local 表,读 Distributed 表。不直接插入 Distributed 表。当然,这样就需要业务在写入前针对 Shard Key 提前拆好数据,分别写入不同的 Local 表。
建表
通过 SQL 建表
分布式表的建表语句示例如下:
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ON CLUSTER clustern( name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr], name2 [type] [DEFAULT|MATERIALIZED|ALIAS expr],... ) ENGINE = Distributed(cluster,database,table,[sharding_key]) [PARTITION BY expr] [ORDER BY expr] [PRIMARY KEY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
- cluster:集群名称,与集群配置中的自定义名称相对应,在对分布式表执行写入和查询过程中,它会使用集群的配置信息来找对应的节点。
- database:对应数据库名称
- table:对应数据表名称,
- sharding_key:分片键,选填参数,在写入数据的过程中,分布式表会依据分片键的规则,将数据分布到各个本地表所在的节点中。关于分片的规则这里进一步说明,分片键要求返回一个整型类型的取值,包括 Int 和 UInt 类型的系列。
分片键使用示例:
-- 分片键可以是一个具体的整型字段 -- 按照用户 ID 划分 Distributed(cluster,database,table,userid)-- 分片键也可以是返回整型的表达式 -- 按照随机数划分 Distributed(cluster,database,table,rand())-- 按照用户 ID 的散列值划分 Distributed(cluster,database,table,intHash64(userid))
最近更新时间:2026.02.11 10:49:14
这个页面对您有帮助吗?
有用
有用
无用
无用