容器服务
容器服务



文档指南

请输入


- 文档首页
 容器服务AI 云原生推理套件Helm 模板 AI 应用EIC 性能测试方法
容器服务AI 云原生推理套件Helm 模板 AI 应用EIC 性能测试方法

EIC 性能测试方法
基于容器服务(VKE)应用中心的应用模板及其指导文档进行部署应用,需要测试弹性极速缓存(EIC)实例最佳性能时,通过本文方法进行测试。
前提条件
已通过 VKE 应用中心的应用模板,部署了大模型应用。详细操作,请参见 AI 云原生最佳实践。
操作步骤
步骤一:停止 GDKV Server 并开启 EIC
基于 VKE 应用中心的应用模板部署完成基于 SGLang 或 Dynamo 的应用后,通过应用模版更新配置文件,停止 GDKV Server 并开启 EIC,然后重新部署应用。
- 登录 容器服务控制台。
- 在左侧导航栏,选择 应用中心 > Helm 应用。
- 在 Helm 应用 页面,筛选目标 集群、命名空间 后,找到 SGLang 或 Dynamo 应用并单击应用名称。
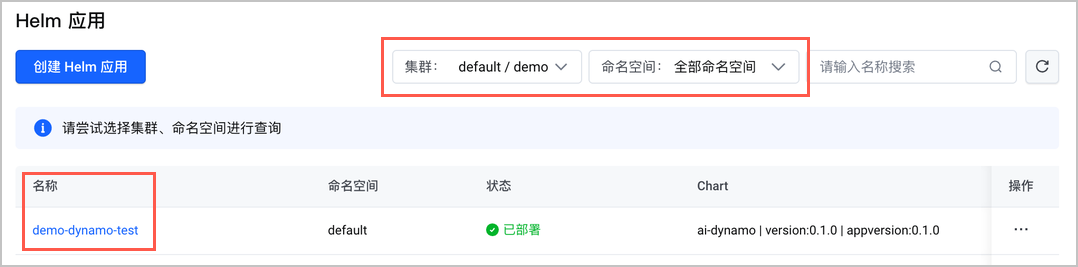
- 进入 Helm 应用详情页 页面后,在页面右上角单击 更新。
- 在 更新 Helm 应用 页面,单击 参数配置 > values.yaml 后的编辑按钮。
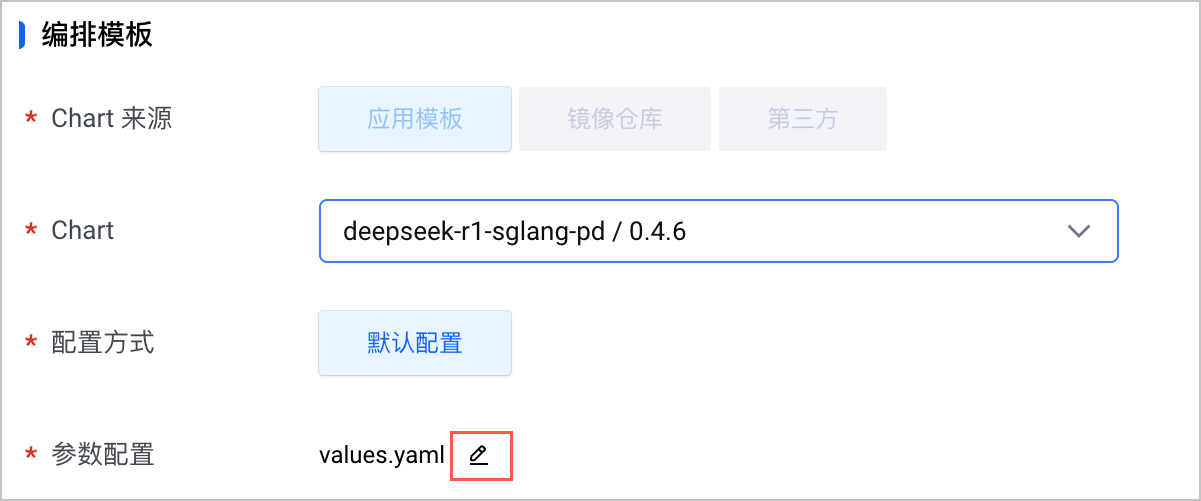
- 找到 GDKV 和 EIC 相关配置,并按照如下代码块及其注释说明修改配置,然后单击 确定 保存变更。
- SGLang 应用,请修改如下配置。
eic: enabled: true # 修改为 true,开启 EIC KV Cache # EIC 实例 ID。登录弹性极速缓存控制台,进入实例详情页面的“实例信息”页签查看。 instanceID: "eicydx97nk******" # EIC 实例的 Endpoint。登录弹性极速缓存控制台,进入实例详情页面的“实例信息”页签查看。 remoteURL: "eic://192.168.xx.xx:12500;192.168.xx.xx:12500;192.168.xx.xx:12500" # EIC 节点网卡。登录弹性极速缓存控制台,进入实例详情页面的“节点列表”页签查看。 netLocalInterfaceNames: "eth1;eth2;eth3;eth4;eth5;eth6;eth7;eth8" # 部署 EIC 的节点所对应的 VKE 节点池 ID。登录容器服务控制台,进入目标集群管理页面中“节点管理 > 节点池”页面查看。 machinePool: "pd0ve352******" gdkv: enabled: false # 修改为 false,关闭 GDKV Server 加载模型。 - Dynamo 应用,请修改如下配置。
gdkv: enabled: false # 修改为 false,关闭 GDKV Server 加载模型。 kvcacheConfig: eic: enabled : true # 修改为 true,开启 EIC KV Cache # EIC 实例 ID。登录弹性极速缓存控制台,进入实例详情页面的“实例信息”页签查看。 instanceId: "eicydx97nk******" # EIC 实例的 Endpoint。登录弹性极速缓存控制台,进入实例详情页面的“实例信息”页签查看。 endpoint: "192.168.xx.xx:12500;192.168.xx.xx:12500;192.168.xx.xx:12500" # EIC 节点网卡。登录弹性极速缓存控制台,进入实例详情页面的“节点列表”页签查看。 ClientMultiNetLocalInterfaceNames: "eth1;eth2;eth3;eth4" modelConfig: local: enable: true # 修改为 true,启动本地缓存模型文件。
- SGLang 应用,请修改如下配置。
- 系统回到 更新 Helm 应用 页面后,单击右下角 确定,开始部署应用。
步骤二:卸载 EIC 实例已有节点
- 登录 弹性极速缓存控制台。
- 在左侧导航栏选择 实例管理,找到对应 EIC 实例后,单击实例名称进入实例详情页。
- 在实例详情页选择 节点列表 页签,查看 EIC 实例已有节点列表。
- 勾选全部节点前的复选框,并单击节点列表下方的 卸载 即可发起节点卸载。
步骤三:扩容 EIC 实例节点
- 在 弹性极速缓存控制台 的 EIC 实例详情页,单击 实例信息 页签。
- 在 实例信息 页签的 配置信息 区域下单击 节点数 参数后的 扩容。
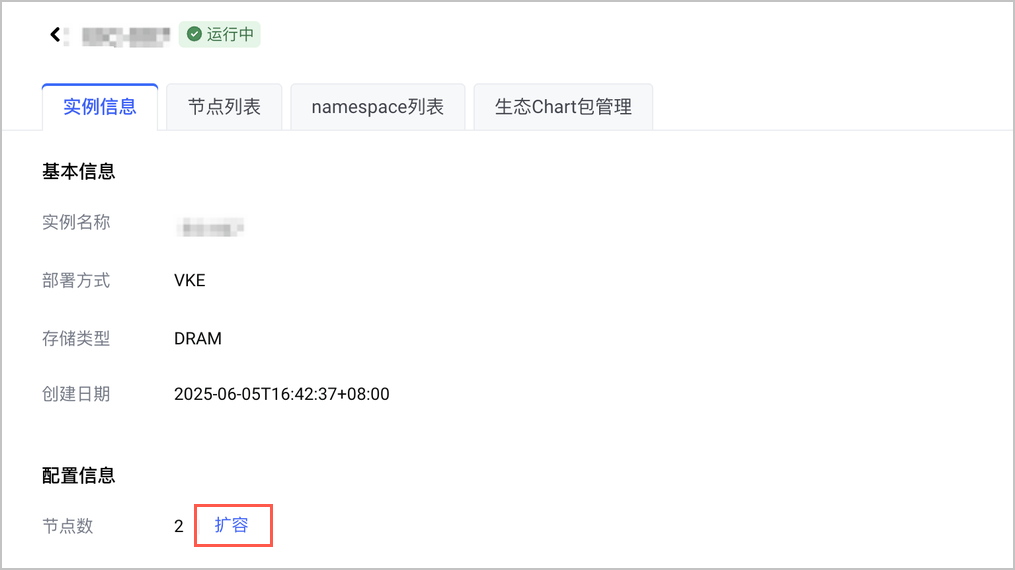
- 在实例的 扩容 页面,勾选需要扩容的节点,当实例当前的节点个数为 0 时,调整节点使用的内存和硬盘容量等参数,然后右下角 扩容实例 即可发起扩容。
建议单台 GPU 机器 DRAM 至少配置 1024 GiB 的内存,以获取更大的推理性能。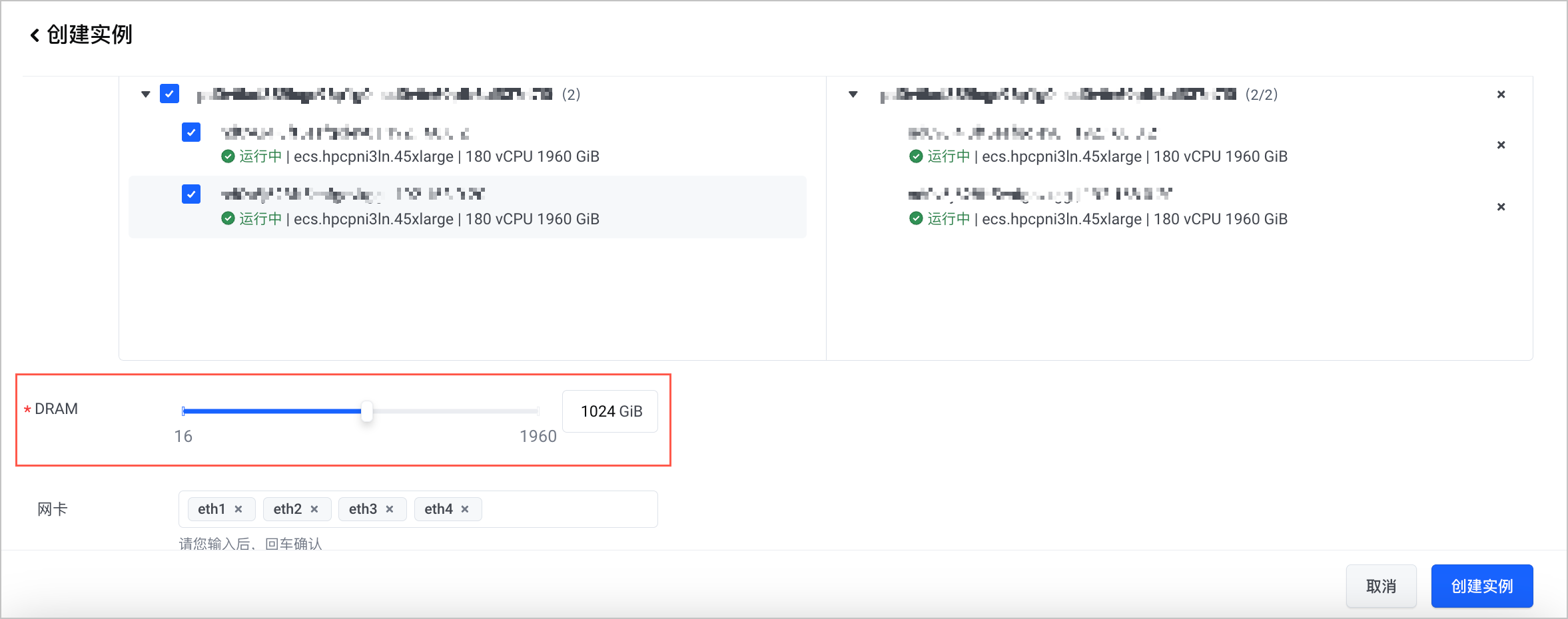
步骤四:性能验证
- 生成 Benchmark测试脚本。
- 下载 vLLM 或者 SGLang Benchmark 测试脚本。
https://github.com/vllm-project/vllm/tree/main/benchmarks - 执行如下命令启动脚本。
脚本内容如下所示。bash test.sh >test.log 2>&1 &# 定义 input 和 output 长度 OUTPUT_LEN=1500 # 创建 logs 目录(如果不存在) model=Deepseek # 测试 GPU 和 EIC 性能时,dir 替换为模型应用相关的日志存储目录 dir=logs_vllm_Deepseek mkdir -p $dir # 定义 request-rate 和 max-concurrency #declare -a input_lens=(200 500 1024 2048 4096 8192 16000 32000) #declare -a request_rates=(1 16 32 48 64 80 128 160) #declare -a max_concurrency=(1 16 32 48 64 80 128 160) #declare -a num_prompts=(4 64 128 192 256 320 512 640) declare -a max_concurrency=(2 4 8 16) declare -a input_lens=(3500 3500 3500) declare -a num_prompts=(16 32 64) SEED=1 # 运行 benchmark 测试 for i in "${!input_lens[@]}"; do for j in "${!max_concurrency[@]}"; do INPUT_LEN=${input_lens[$i]} RATE=${max_concurrency[$j]} CONCURRENCY=${max_concurrency[$j]} PROMPTS=${num_prompts[$i]} SEED=$((SEED + 1)) echo "Running benchmark with input len: $INPUT_LEN, output len $OUTPUT_LEN, request rate $RATE, concurrency $CONCURRENCY, prompts $PROMPTS, first round" python3 benchmark_serving.py --backend vllm \ --tokenizer /models/deepseek \ --model $model \ --base-url http://127.0.0.1:8080 \ --endpoint /v1/completions \ --metric_percentiles '50,90,95,99' \ --goodput ttft:5000 tpot:250 \ --num-prompts $PROMPTS \ --request-rate $RATE \ --max-concurrency $CONCURRENCY \ --random-input-len $INPUT_LEN \ --random-prefix-len 0 \ --random-output-len $OUTPUT_LEN \ --dataset-name random \ --ignore-eos \ --seed $SEED \ --save-result \ --result-dir ./$dir \ >> $dir/${model}_${CONCURRENCY}_${PROMPTS}_${INPUT_LEN}_${OUTPUT_LEN}_firstround.txt 2>&1 sleep 1 echo "Running benchmark with input len: $INPUT_LEN, output len $OUTPUT_LEN, request rate $RATE, concurrency $CONCURRENCY, prompts $PROMPTS, second round" python3 benchmark_serving.py --backend vllm \ --tokenizer /models/deepseek \ --model $model \ --base-url http://127.0.0.1:8080 \ --endpoint /v1/completions \ --metric_percentiles '50,90,95,99' \ --goodput ttft:5000 tpot:250 \ --num-prompts $PROMPTS \ --request-rate $RATE \ --max-concurrency $CONCURRENCY \ --random-input-len $INPUT_LEN \ --random-prefix-len 0 \ --random-output-len $OUTPUT_LEN \ --dataset-name random \ --ignore-eos \ --seed $SEED \ --save-result \ --result-dir ./$dir \ >> $dir/${model}_${CONCURRENCY}_${PROMPTS}_${INPUT_LEN}_${OUTPUT_LEN}_secondround.txt 2>&1 sleep 1 echo "Running benchmark with input len: $INPUT_LEN, output len $OUTPUT_LEN, request rate $RATE, concurrency $CONCURRENCY, prompts $PROMPTS, finished" done done
- 下载 vLLM 或者 SGLang Benchmark 测试脚本。
- (可选)关闭 EIC,对比验证性能。
若需要对比测试开启 EIC 前后的效果,可以参考 步骤一:停止 GDKV Server 并开启 EIC 中的操作找到应用的 YAML 配置文件,并按如下代码及其注释说明关闭 EIC 后,再次压测对比性能。- SGLang 应用
eic: enabled: false # 修改为 false,关闭 EIC KV Cache。 - Dynamo 应用
kvcacheConfig: eic: enabled : false # 修改为 false,关闭 EIC KV Cache。
- SGLang 应用
最近更新时间:2025.06.13 15:17:03
这个页面对您有帮助吗?
有用
有用
无用
无用