火山引擎智能创作语音团队SAMI(Speech, Audio and Music Intelligence)近日发布了新一代的低延迟、超拟人的实时AI变声技术。不同于传统的变声,AI变声是基于深度学习的声音转换(Voice Conversion)技术来实现的,可以实现任意发音人的音色定制,极大程度保留原始音色的特点。
在CPU单核上就能做到极低延迟的实时输入实时变声,就像“柯南领结”一样;
能够高度还原输入语音的抑扬顿挫、情感、口音,甚至连轻微的呼吸、咳嗽声也能还原;
媲美真人的高保真音质,以及高度的目标音色一致性。
从语音合成到声音转换:探索多元声音玩法
语音合成作为人工智能的一个重要分支,旨在通过输入文字,经由人工智能的算法,合成像真人语音一样自然的音频,该技术已被广泛地应用于音视频创作场景中。相比语音合成,声音转换创造了新的语音交互形式:其不再需要输入文字,而是根据用户输入的说话音频,将音频中的音色转换到目标发音人上,并保持说话内容、韵律情感等一致。相较于输入文本,输入音频包含了更丰富的副语言信息,例如各个段落的情感、抑扬顿挫、停顿等。声音转换能够做到改变音色的同时,将这些副语言信息很好地还原。
同基于深度学习的语音合成一样,声音转换的模型也由声学模型(acoustic model)和声码器(vocoder)组成。声学模型通过内容编码器从输入音频中提取出发音内容序列,并通过音色编码器从参考音频中提取出音色特征,最后通过声音转换模型生成带有输入音频内容和参考音频音色的频谱;声码器负责将声学模型生成的频谱还原为能够被设备直接播放的音频采样点。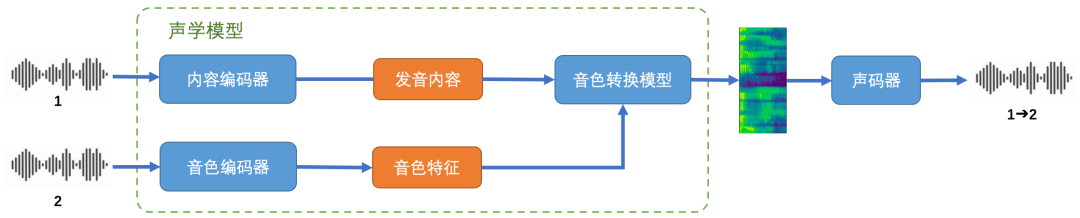 声音转换流程示意
声音转换流程示意
面向实时场景的声音转换模型优化
相较于非实时场景下对完整音频的声音转换,实时声音转换有着更加丰富的落地场景。典型场景包括直播、虚拟人这类实时交互的娱乐场景,变声结果需要在很短延迟内实时流式生成,才能保证音画同步。
实时声音转换的难点在于:1. 模型在每个时刻只能获取到很短的未来音频片段,因此发音内容的正确识别更加困难;2. 流式推理的实时率(计算时长/音频时长)需要稳定小于1,因此在设计模型时需要更加关注推理性能 。这给研发人员带来了更大的挑战,一方面需要通过设计合理的模型结构来降低模型感受野和推理延时,另一方面需要尽可能保证变声的发音内容、音色和音质不受影响。
为了达到上述要求,研究人员对模型进行了一系列改进,使得模型的首包延时压缩到250ms左右。实时声音转换的整体框架如下: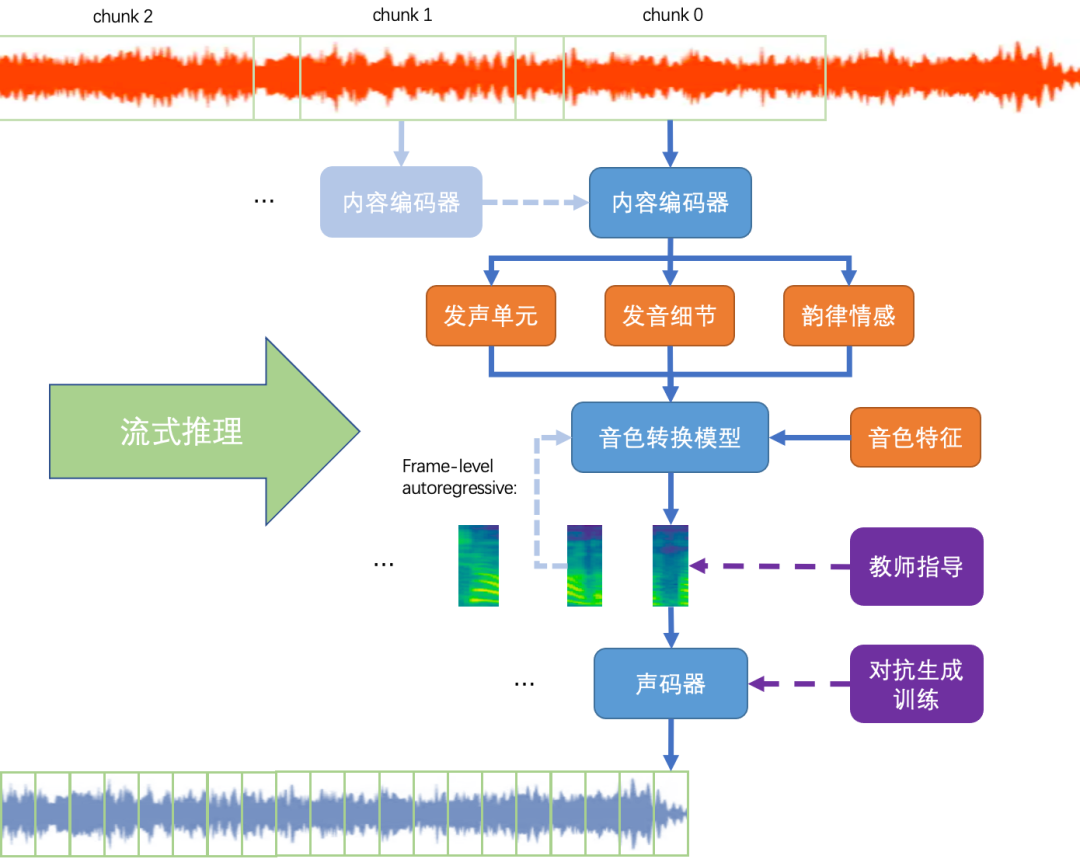 实时声音转换整体框架
实时声音转换整体框架
对于内容编码器,研究人员采用细粒度发音提取模块代替了传统基于音素后验概率的方法,使得更多的发音细节、韵律情感能够被保留下来,显著降低了对模型感受野的要求;对于声音转换模型,研究人员结合了chunk级别的信息编码和帧级别的自回归解码,并引入了基于教师指导的训练机制,从而确保生成频谱的发音、音质和音色足够好;对于声码器,研究人员通过精巧的模型结构设计大大压缩了感受野,并通过对抗生成训练提高了生成音频的自然度。
现实版“柯南领结”:各种复杂场景不在话下
现实的语音交互中往往包含许多复杂的场景,使得现有大部分的AI变声系统的转换结果变得极不自然。例如,当用户输入中包含叹气、咳嗽这类声音时,现有系统倾向于对其过滤而非保留,从而导致用户想表达的副语言信息丢失;现有系统的跨域性能较差,导致用户进行多语种/方言输入时,无法转换出正确的内容;现有系统在低延迟场景下的转换结果容易出现发音错误与音色不稳定的问题。
相较于现有系统,本系统在各个场景下的转换效果均显著提升。以下视频演示了无网环境下在Macbook上的实时流式变声效果。
火山引擎的新一代AI变声系统对于复杂场景的适应性显著提升。这项声音转换服务可以支持云端在线服务形式输出,也支持本地化部署。未来在虚拟人、短视频玩法、客服服务、直播互动玩法上有着很大的落地空间。
火山引擎音频技术主要致力于语音合成、音频理解与处理、音乐理解与编辑、音乐生成等技术的研究和应用,用AI赋能创作者,激发创作灵感,为用户提供全新的交互体验,发掘声音的无限可能。