近日,国际顶级学术会议ACL 2021正式颁发了大会奖项,字节跳动AI Lab的机器翻译技术论文当选今年度“最佳论文”。这是ACL成立59年以来,中国科学家团队第2次赢得最高奖项。
ACL 2021由国际计算语言学协会举办,是自然语言处理(NLP)与计算语言学领域最高级别的学术会议。本次共有3350篇论文参与评选,最终只有21.3%的论文录用。
在这篇论文中,字节跳动技术团队提出了“面向机器翻译的最佳运输词表学习方案”(Vocabulary Learning via Optimal Transport for Machine Translation,简称VOLT)。接下来,该方案将在火山翻译中逐步应用。
如今AI风靡全世界,AI模型的强度往往和算力成正比,占用大量算力资源、消耗大量电能去训练超大模型成为一股风潮,而且确实创造了巨大的效益。
但在字节AI Lab看来,在实现同样效果的前提下,降低模型复杂度、推动节能环保,也是有价值的一个研究方向。

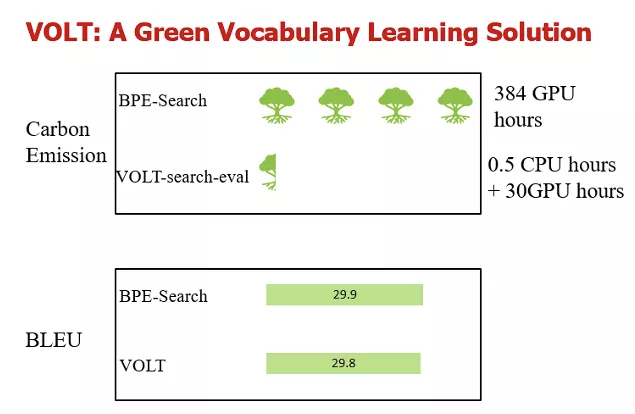
从VOLT的测试效果来看,其对促进AI产业节能环保极具潜力。
以主流词表BPE为例,业界普遍会通过大量自然语言处理下游任务的训练以寻找最优大小。相比之下,使用VOLT方案可以节省大约92%的算力,这同时意味着所需电能的大量减少。
ACL的评审们对这篇论文的评价是:
想法新颖;
显著减少词表的学习和搜索时间;
有效性已经通过几个实验得到了很好的证明。
ACL官方评审意见认为,字节跳动的VOLT方案对机器翻译中一个重要问题提出了有效且新颖的解决方案,能显著减少词表的学习和搜索时间,相信其不仅会在研究界产生重要影响,在工业应用方面也有着巨大潜力。
ACL 2021官方信息显示,此次大会除了字节跳动,华为、腾讯、谷歌、微软、亚马逊等科技公司也投递了论文。
字节跳动的论文为何能从中脱颖而出?
VOLT最突出的贡献是解决自然语言处理(NLP)的两个基本问题:
什么是最优词表;
如何生成最优词表。
最优词表:即以边际收益定义词表评价指标MUV
子词级别词表的效果在多个任务上已经得到了验证,由此,论文作者表示子词是目前来说比较好的选择。
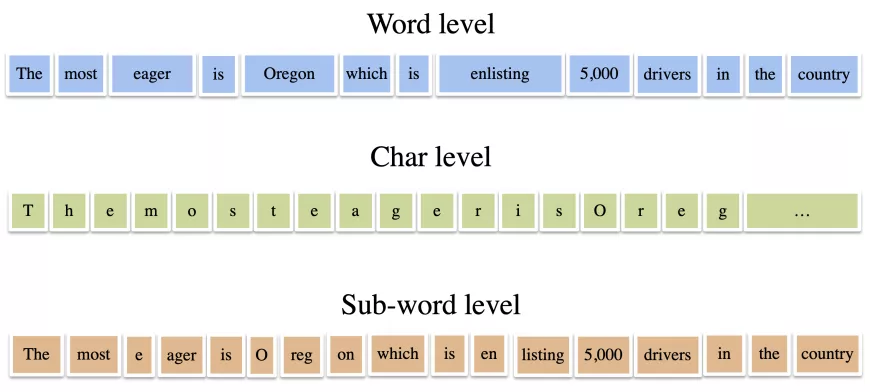
相比于传统的词为基础单位的词表,子词规模小不会面临稀疏标记(token)的问题。其中,稀疏标记是指在语言中出现概率比较小的子词。
相比于字结构的词表,子词也不会面临熵太大语义无法区分的问题。于是,在确定最优词表的评价指标方面,论文作者综合考虑了信息熵和词表大小这两个主要因素。
信息熵也可以理解成为蕴含在每个字中的平均语义含量。直观上理解信息熵越小表示每个字或者词表示的信息越简单,那么更加利于模型学习。
论文作者使用基于字的熵计算方式来评估该属性,其中v为词表,i为词表中的标记,P为标记在训练集出现的频率:
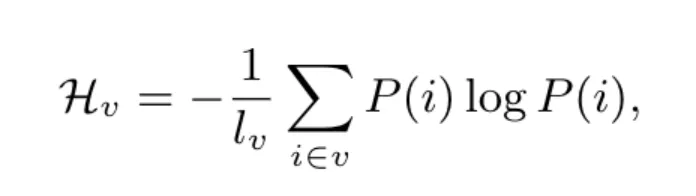
词表大小,机器学习对训练数据的数量要求很高,稀疏标记的出现概率较低,因此稀疏标记越多,需要的训练数据往往也就越多。在基于频率的方法下,词表越小,稀疏标记越少,参数也越少,因此,小的词表更加有利于模型学习。
然而,信息熵和词表大小不可以兼得。词表越大,所需参数越大,稀疏标记越多,但是信息熵在减小。
为了建模这种平衡,论文作者为此引入了边际收益的概念。边际收益衡量了付出单位代价所能获得的利益的数量。边际收益越大,那么投入产出比越高。
将信息熵看成是边际收益中的利益,词表大小看成是边际收益中的代价。随着词表的增加,不同大小的词表的信息熵收益是不同的。
因此,利用边际收益的概念便可以对衡量词表质量的指标MUV进行定义,并且可以观测到MUV指标和下游任务的相关性。
生成最优词表:将词表搜索变为最优运输问题
在确定词表评价指标MUV之后,学习最优词表的问题可以粗略地等价为寻找具有最大MUV的词表问题。但是词表搜索空间不仅庞大,而且是离散空间。
为了解决这一问题,论文作者将词表搜索转化为最优运输的过程。比如cat在训练集中出现了20次,那么cat需要20个c,20个a,和20个t来组成该标记。
为了避免不合法的搬运,论文作者将不合法的搬运设为无穷大(比如字e搬运给标记cat是不合法的)。由于字的个数是有限的,有一些标记候选就无法拿到对应的字,那么这些标记将会从最终的词表中踢出去。
为了将词表学习的问题转化成为最优运输的代价,就需要进行一些重构操作了:
MUV可以理解成为熵对词表大小的一阶导数,为了建模连续的导数,论文作者引入了相对分数来模拟导数:
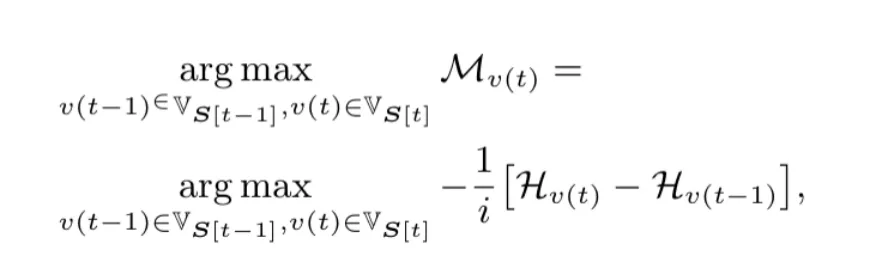
H代表的是信息熵,分子是信息熵的相对变化量,而分母中的i代表词表大小的变化量,S是一个递增序列,每个元素代表以该时刻大小为上届的所有词表组合。因此对于每个步骤来说,都存在一个具有最大MUV分数的词表,只要对所有的步骤做遍历,就可找到最优词表。
为了进一步降低求解难度,论文作者对每一步的求解公式做了一个近似:
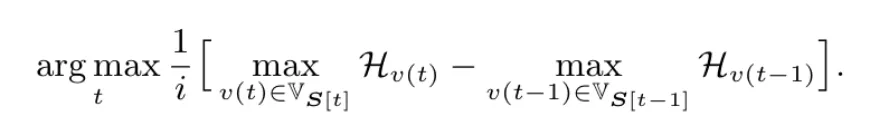
因此,每个步骤的问题就转化成了每个步骤寻找熵最大词表的问题。接着使用基于熵的最优运输解法就可以将最优运输的目标定义成为寻找熵最大词表的问题。
如此便可以使用标准的求解算法去求解该公式:
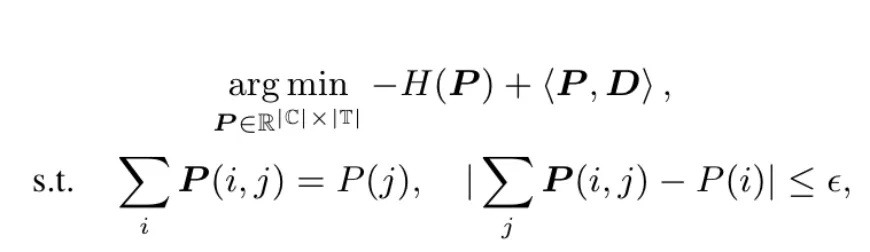
找到词表的最大熵并且计算出当前的最大MUV分数,最后遍历所有的步骤即可找到具有最优的MUV的词表。
该方法不需要下游任务训练,因此非常简单高效。
在从双语翻译的结果上看,新方法学到的词表比经常使用的词表小很多,效果也很有竞争力。
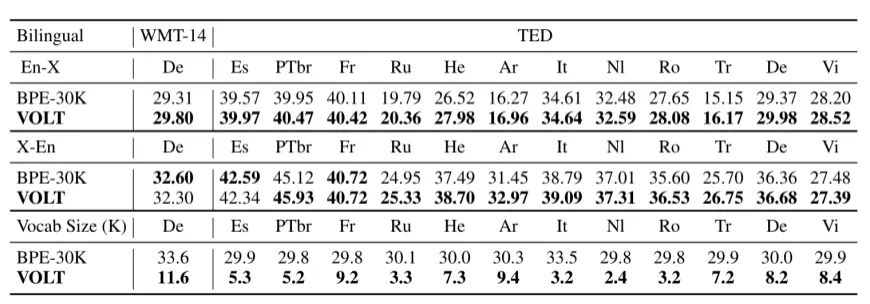
从多语翻译的结果上看,在三分之二的数据集上效果也是较好的。
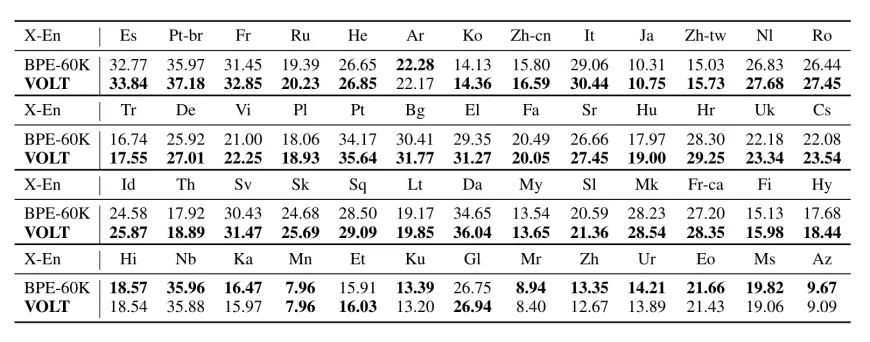
接下来,字节团队的论文研究成果也会在火山翻译中逐步得到应用。主要为飞书、今日头条等产品和火山引擎的「企业级客户」提供机器翻译支持。
下图是火山翻译的技术应用于西瓜视频的翻译效果。
这是一个数学教学视频,原视频中带有人工翻译的字幕。
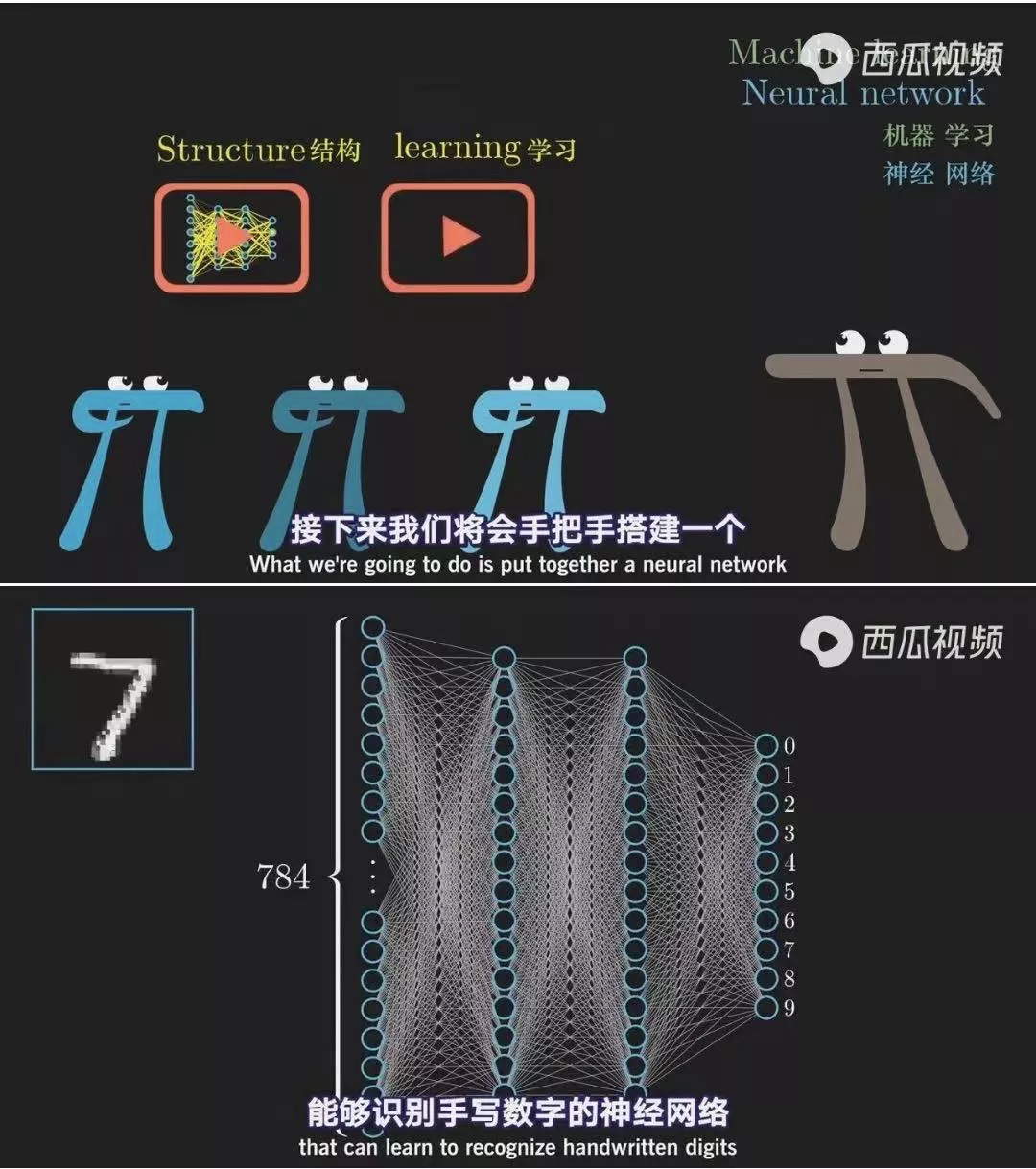
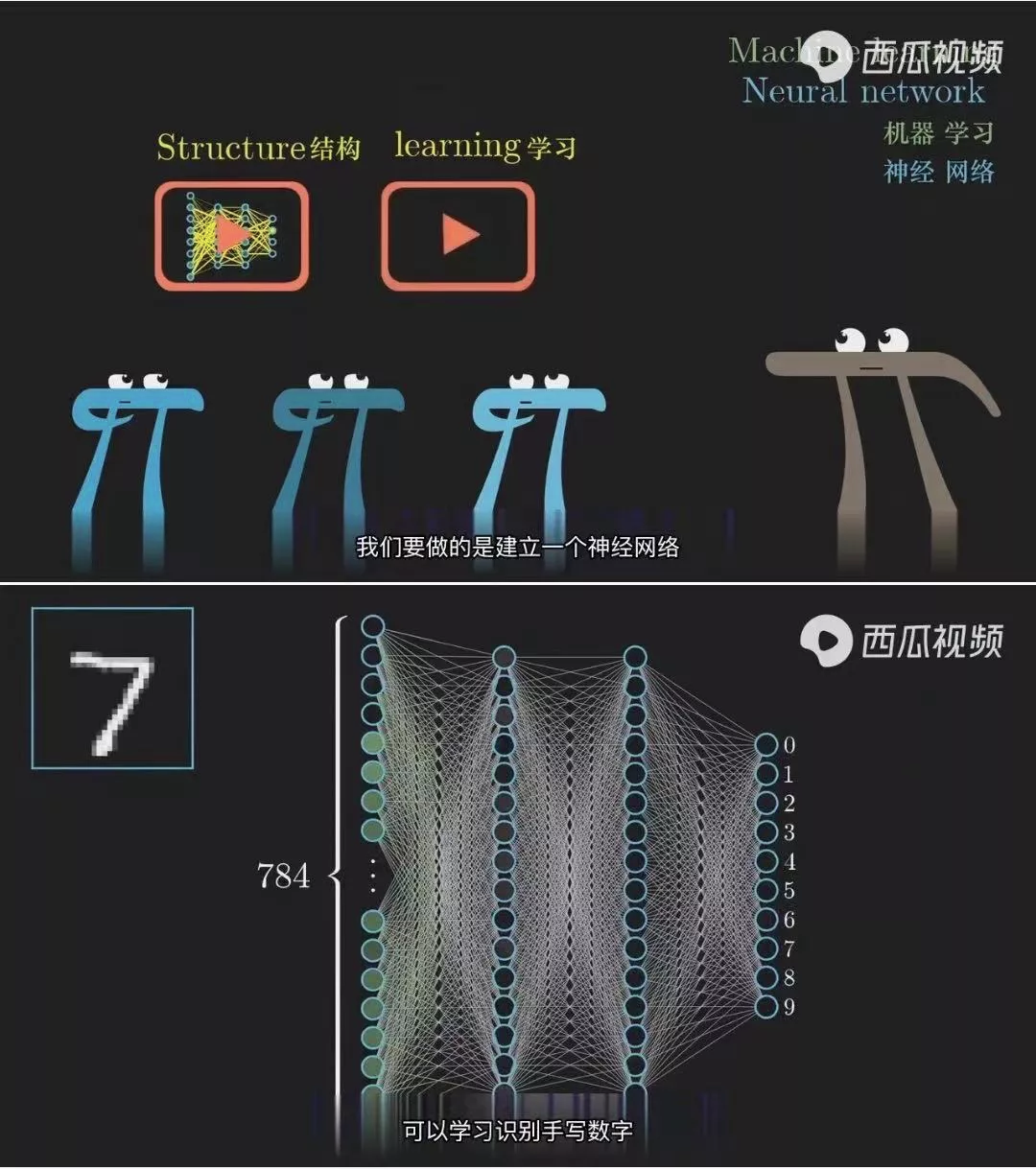
这是经过火山翻译后的视频字幕,其翻译质量并不比人工翻译逊色。
2021年以来,火山翻译实现多项重要技术突破,研发出支持150个语种互译的大规模翻译模型mRASP2。

项目地址: https://github.com/PANXiao1994/mRASP2
此外,火山翻译还对外开源了当前业界最快的推理和训练引擎LightSeq2.0,以及端到端语音翻译工具包NeurST,获得开源社区的广泛好评。

项目地址: https://github.com/bytedance/lightseq
LightSeq在GitHub上已经获得了1500星。

项目地址: https://github.com/bytedance/neurst
在此前由ACL举办的机器翻译大赛WMT2021上,火山翻译以独创的「并行翻译」系统参赛,夺得德语到英语方向比赛自动评估第一名。
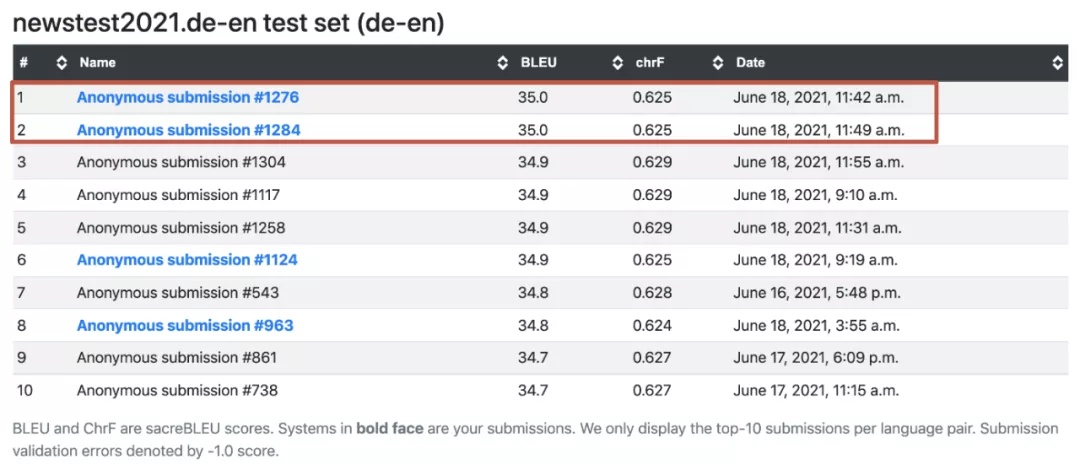
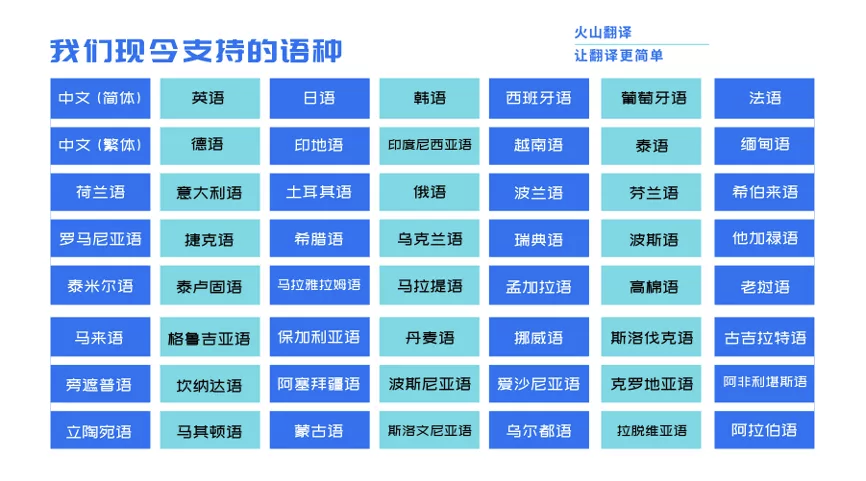
「并行翻译」在国际赛事中首次亮相,就击败了从左向右逐词翻译的传统技术,打破后者在机器翻译领域的绝对统治地位,这项技术的论文也得到ACL 2021大会收录。目前,火山翻译已支持56个语种、3080个语向的翻译。
火山翻译的技术,是从字节跳动团队多年来在机器学习和自然语言的深耕中沉淀出来的,目前,火山翻译已经形成从前沿研究、产品研发到用户反馈的闭环。
除此之外,字节跳动业务覆盖150个国家和地区,研发团队分布在全世界多个国家,工作中也在使用自己打造的产品来跨语言沟通。
全球化业务+全球化人才的加持下,火山翻译将继续精进技术,为用户提供更好的服务。