随着各行各业企业核心业务数字化、精细化部署,云网络的流量出现了持续的增长,同时也对网络性能提出了更高的要求:集群规模越来越大、云主机数量增加,每个云主机都可能对网络的功能和性能有不同的要求。OVS(Open vSwitch)是应用广泛的虚拟交换机,以其强大的功能,满足不同虚拟机的需求。但OVS在实现强大完善功能的同时,架构较复杂和臃肿,在转发性能方面越来越不符合企业用户预期。
那么在这样的情况下,vSwitch性能如何突破?
在刚刚结束的2022 ChinaOpenInfra Days ,来自火山引擎云网络产品技术负责人林科,为大家分享字节跳动内部成功的技术探索与实践,全部分享内容如下:
大家好,我是来自字节跳动基础架构团队的林科,目前在负责火山引擎云网络产品的相关研发工作。
火山引擎是字节跳动旗下的云服务平台, 将字节跳动快速发展过程中积累的增长方法、技术能力和工具开放给外部企业,帮助企业在数字化升级中实现持续增长。作为云服务平台的基础,火山引擎云网络采用了全自研架构,具备了丰富的产品能力,提供了灵活、安全组网的大规模云原生网络。
vSwitch是VPC产品中关键的一环,用于实现丰富特性的同时还要支持极致性能。在云网络产品演进过程中,我们针对高性能vSwitch架构做了大量的探索和尝试,所以今天想和大家分享下其中一些实践和思考。
火山引擎在初期,希望快速构建产品能力,同时也考虑到高性能诉求,所以第一版vSwitch采用了CX5 Kernel OVS Offload方案。期间和Mellanox一起深入合作,针对CT Offload、内存开销、集群规模等方面做了大量的优化工作,在使用2HT CPU的情况下,转发性能达到了1800万pps,并上线了多个1万节点以上规模的生产集群,这应该也是目前业界最大规模的Offload OVS的线上应用。
Offload OVS很好的解决了0-1的问题,但随着业务的复杂化,Offload OVS面临的问题和挑战也日益突出。集群规模在不断扩大,网卡硬件表项的容量问题是个无法规避的问题,虽然网卡硬件可以使用host mem作为cache,但表项规模超过硬件容量后,无论是性能还是稳定性都带来了巨大挑战,revalidator机制在大规模场景下也会面临规模问题,我们在线上遇到过多次revalidator处理不及时导致全量硬件表项被清空的问题。另外大规模表项同时也会消耗大量的内存,虽然我们做了很多的内存优化,但200万session依然需要消耗15G左右内存。此外Offload OVS的新建性能瓶颈、CT Offload的稳定性风险、卸载带来的运维复杂度,这些问题在Offload OVS架构下很难解决。
为了缓解Offload OVS问题,我们引入了DPDK OVS,希望通过软件架构获得更多的灵活性和可控性。针对DPDK OVS我们做了大量优化,例如DPDK OVS原生的CT性能很差,因此针对CT做了大量改造和优化,最终在4HT CPU的情况下,转发性能可以到了300万pps。此外,我们也在DPDK OVS上实现了不断流的热升级和流热迁移能力,使DPDK OVS的运维能力有了显著提升。
在稳定性和可运维方面,DPDK OVS相比Offload OVS有了很大的改善,但依然面临着很大的挑战。虽然做过很多性能调优,但300万pps转发性能基本上是4HT的极限了,而且随着session数量的增加,转发性能还会快速下降,这个性能对目前的云网络来说是远远不够的。虽然分配更多的CPU给OVS可以一定程度提升性能,但这个在成本上是无法接受的。
除了性能以外,使用DPDK OVS过程中遇到的更大挑战其实是来自OVS的自身架构。OVS架构非常的灵活,功能也非常强大,这些是OVS的优点,但也正是因为这些优点让OVS架构变得过于臃肿和复杂,而我们一般需要用到的功能都非常的少且是明确的。这些问题使基于OVS的定制开发和优化成本变的很高,另外很多高阶的产品特性基于OVS的通用架构也很难实现。例如如何在多租户场景下实现变配隔离、如何在单个VPC内支持超过100万的私网IP、以及如何实现FlowLog和vTrace等等。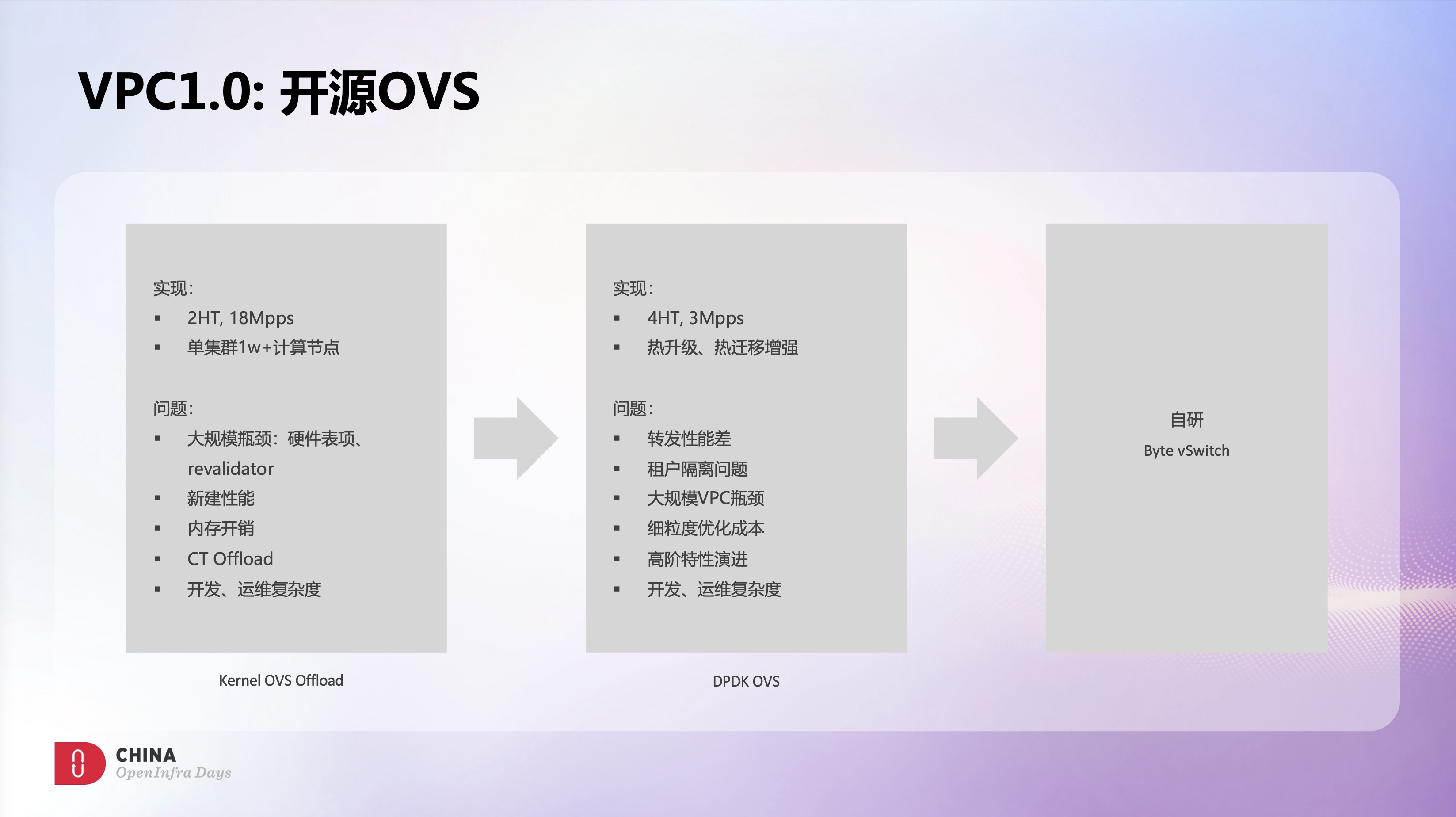
综合来看,OVS非常适合快速构建产品的基础能力,但很难构建产品的核心竞争力。基于过往的这些OVS使用经历,我们决定自研一款vSwitch,来解决我们遇到的这些问题和挑战。
我们希望自研vSwitch能够通过低成本的方式满足业务的高性能需求;随着集群规模的不断扩大,可运维会逐渐演变成vSwitch的最大挑战,因此希望它有很好的可运维能力;也希望能基于自研vSwitch构建产品的核心竞争力,在丰富VPC产品能力的同时,解决VPC的规模问题。
基于上述目标,我们自研了Byte vSwitch,简称BVS。不同于OVS的通用架构,BVS是一个业务驱动的vSwitch,目标定位只用于云上VPC场景,没有像OVS那样使用OpenFlow协议,也没有OVS那么丰富的特性级。我们希望通过简化场景和功能,以换得简单的实现和极致的性能,这本质上也是通用化和定制化间的一个取舍。
在实现上,BVS设计了一套高性能的转发架构,有一层抽象转发的快路径和一层感知业务的慢路径。快路径通用且轻薄,具备了超高的转发性能;慢路径贴近业务,能实现各种复杂的业务逻辑。整个快路径采用了无锁架构,全程使用了批量处理,同时做了大量的cache优化,以及vxlan offload、tso offload、checksum offload等硬件卸载,使BVS单核具备极致的转发性能,多核性能也可以接近线性的水平提升。
另外,我们也针对常用的网络算法做了大量优化。DPDK原生的LPM和HASH算法内存开销比较大,我们重写了LPM和HASH算法,在不影响性能的前提下使内存的消耗极大降低。DPDK原生的ACL算法在展开时非常耗时,也会占用大量临时内存,我们也自研了ACL算法,使ACL展开时的耗时和内存开销都得到了极大改善。另外DPDK原生的QoS算法是有锁的,多线程并发场景会导致转发性能骤降,我们也自研一套近乎无锁的QoS算法,即使在高并发场景下也不会特别影响性能。
此外,基于之前OVS的使用经验,BVS在热升级、热迁移、可视化、自动化诊断等方面做了大量工作,后面的内容里也会针对这些能力来做详细介绍。
最后,基于BVS灵活的架构设计,我们可以实现各种特性,极大的丰富VPC的产品能力和竞争力。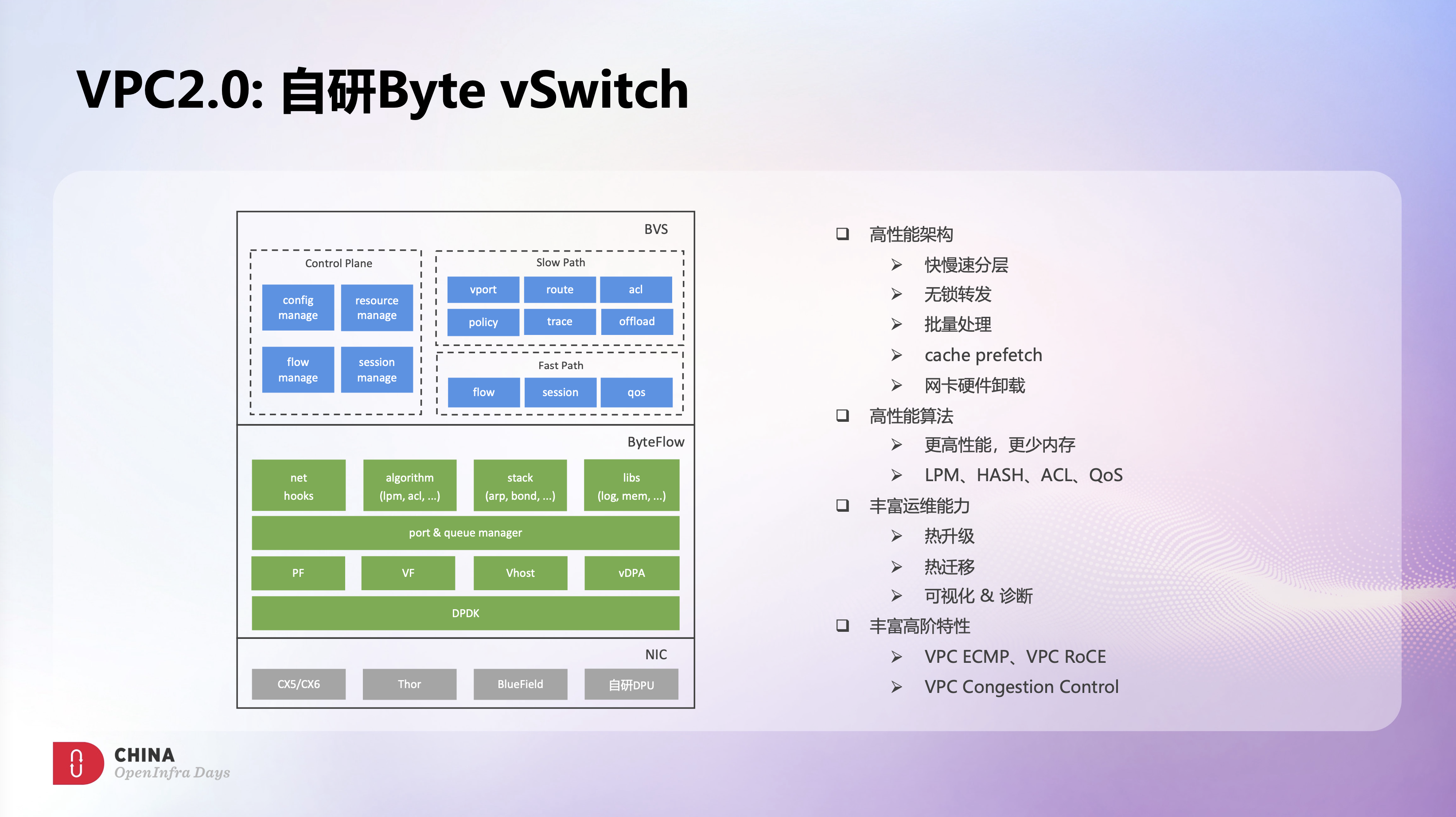
左边这张图是BVS的整体架构图,除了最上面的BVS业务层外,我们在设计BVS的同时也设计了ByteFlow这个组件。在云网络产品中,除了BVS,我们还有VPC网关、LB网关等大量数据面组件,这些组件在底层硬件适配、网络算法库、网络基础库等方面有很多共性,我们希望通过ByteFlow平台来抽象和统一这些底层基础能力。这样一方面可以沉淀、积累和复用;另一方面也可以简化上层业务开发,使业务和底层硬件松耦合。也正是基于ByteFlow的这层抽象,BVS可以在不感知底层硬件的情况下,完成和不同厂商、不同形态网卡硬件的集成。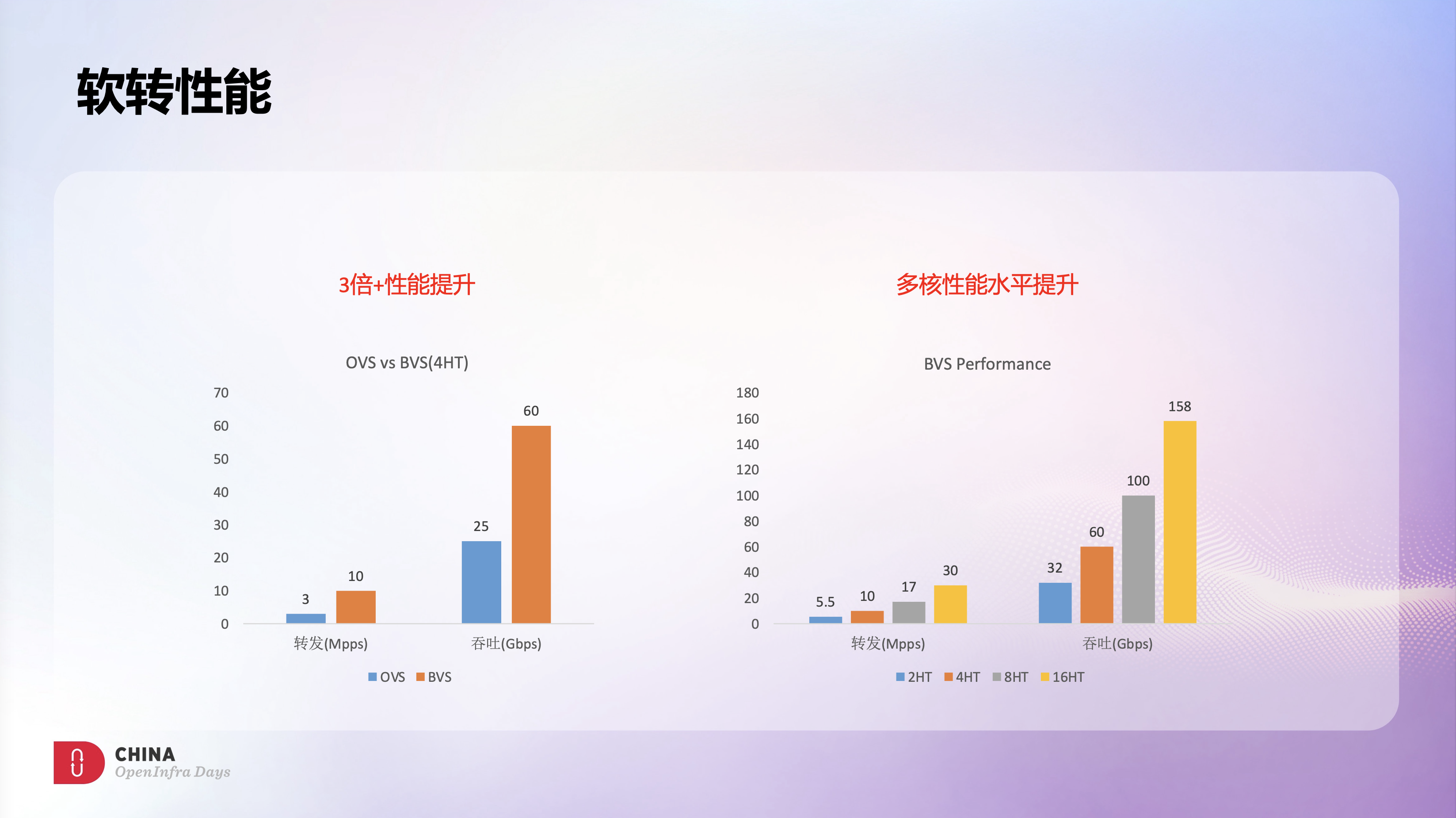
通过架构和算法等多方面的优化,BVS软转发性能相比OVS有3倍以上的提升,4HT场景下,可以达到1000万pps的小包转发,以及60Gbps的吞吐。
此外,依托BVS快路径的无锁设计和cache优化,随着转发CPU的增加,BVS的转发性能可以接近线性的水平提升,16HT场景下,可以达到3000万pps的小包转发,以及158Gbps的吞吐。
我们评估了下线上的业务情况,4HT基本能满足绝大部分业务的网络需求,部分非网络敏感类业务只要2个HT就够了。通过自研BVS,只要原来OVS一半的网络成本,就能实现比之前OVS更高的转发性能,很好的解决了OVS的性能瓶颈问题。
不断流热升级是之前OVS上遇到的一个痛点,也是后续BVS可以快速迭代的一个关键能力。我们希望BVS热升级能达到两个目标:一个是热升级的稳定性,BVS后续部署规模可能是10万+级别的,热升级的成功率是保障BVS可运维的一个关键。另一个是业务无感知,具体需求是升级不断流,整机downtime要小于100ms,而且downtime越低越好。这也是BVS可以持续迭代的一个基础,如果每次热升级都是业务有感的,那BVS基本上就没法演进了。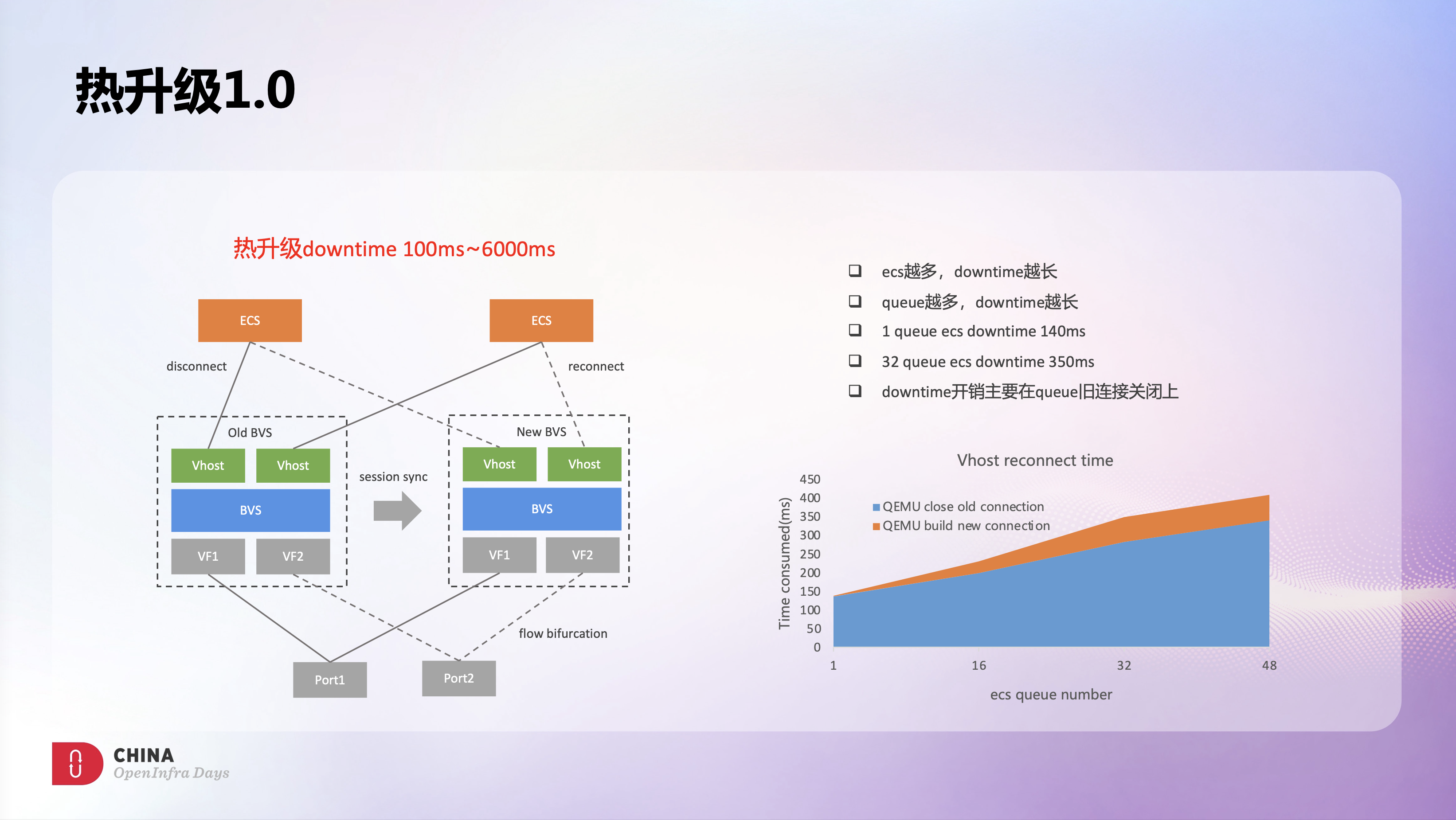
基于上述目标,我们设计如图所示的热升级方案,这应该也是目前业界比较常用的一种热升级方式。热升级时会启动一个新的BVS进程,老进程会把全量session同步给新进程,这样可以实现升级前后存量连接的不中断。物理网口方向,通过网卡硬件的flow redirect能力可以实现快速切流。Vhost方向,升级过程中老进程会断开和Qemu Vhost的连接,然后通过重连机制连到新的进程上,从而完成了热升级的流量切换。此外我们在热升级流程中也做了详细的precheck和postcheck,资源预留不足或系统异常时都不会启动热升级,热升级失败后会自动回滚,回滚不会对业务有任何影响,这些check和回滚机制显著提升了热升级的稳定性和成功率。
但测试发现这个热升级方案的downtime会比较长,极端情况下downtime会到6s以上。另外也发现单节点上的ecs越多downtime越长,同样地,单台ecs上queue个数越多downtime也变长,例如一台单queue ecs的downtime大概是140ms,一台32 queue ecs downtime会达到350ms。通过更多的测试和分析,我们发现downtime的主要开销在queue旧连接的关闭上,上图中右下角可以看到不同queue个数下旧连接关闭和新连接建立的耗时情况。
Qemu与Vhost之间的连接需要断开和重连,这个是Qemu的基础实现,优化空间不大,所以我们在想是不是可以有别的方法可以来解决这个问题。如果重连这么慢的话,那是不是可以不用重连机制,而是通过迁移机制把存量的queue信息从旧的BVS进程迁移到新的BVS进程呢?
于是我们针对DPDK vhost user代码做了些定制开发,引入这种基于迁移的同步机制,并给他取了个名字叫VSM。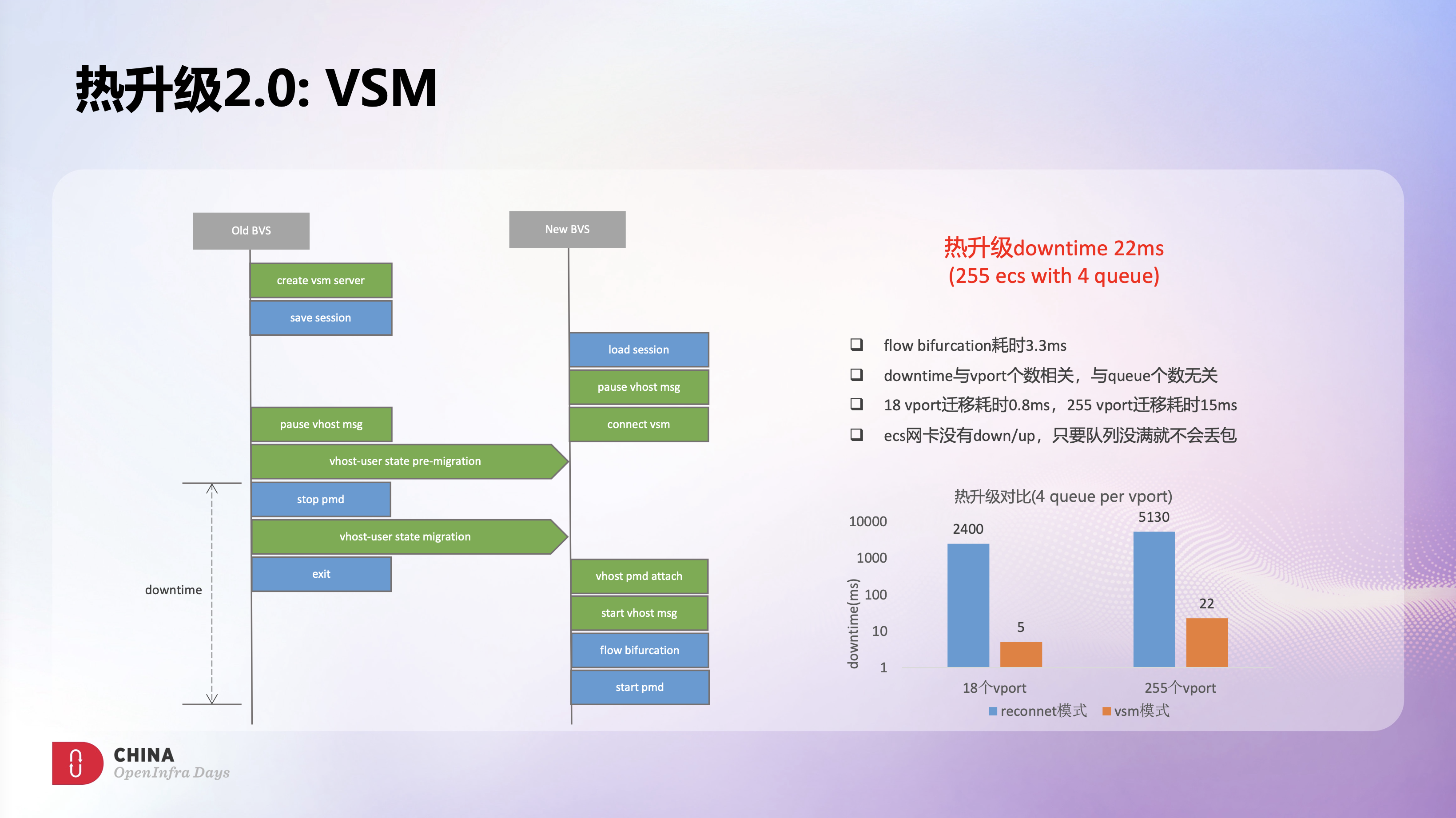
这里描述了基于VSM的BVS热升级流程,相比之前的热升级方案,新的BVS进程会通过socket把存量的queue连接信息从老进程迁移过来,从而避免了Vhost断开和重连的开销。
新方案的downtime相比旧方案有明显优化,18台4 queue ESC场景的downtime从之前的2.4s降级到了5ms,这个场景下flow redirect是主要开销,大概耗时3.3ms。255台4 queue ecs场景的downtime从之前的5.1s降低到了22ms,整体downtime主要和vport个数相关。我们进一步细化了升级过程中每个阶段的耗时,发现18个vport迁移耗时大概是0.8ms,255个vport迁移耗时大概是15ms,可以看到整个迁移过程的性能是非常高效的。另外这个新方案中,ESC网卡是没有down/up的,因此只要队列没满就不会丢包,所以网络的中断时间也非常的短。
综合来看,VSM机制很好的解决了downtime问题,而且非常的稳定,使每次热升级downtime可以控制在20ms以内,实现了业务的无感升级。
不断流热迁移是之前OVS上遇到的另一个痛点,也是ECS的一个关键运维能力。热迁移对业务是透明无感知的,迁移前后的存量连接不能受到影响,所以我们在BVS上支持了vport级别的session同步功能,热迁移开始时会做一次全量的session同步,全量同步完后会实时同步增量session,从而保证两边的session是一致的。
但是测试发现有了session同步后,热迁移还会有1-2s的downtime。这个是因为热迁移后集群内部分节点保存的仍是旧的vm location信息,因此还会持续发送流量到旧的BVS节点,从而导致了流量不通。而集群内全量节点完成VM location收敛的时延是不确定的,这个和集群的规模、业务负载都是相关的。所以我们在BVS上开发了relay转发功能,旧的BVS节点收到迁移VM的流量后会relay转发到新的BVS节点,从而避免了VM location全局收敛时延导致的丢包。
通过session同步和relay转发,热迁移downtime得到了极大的优化,因网络导致的downtime在整个热迁移过程中只占到了很小的比例。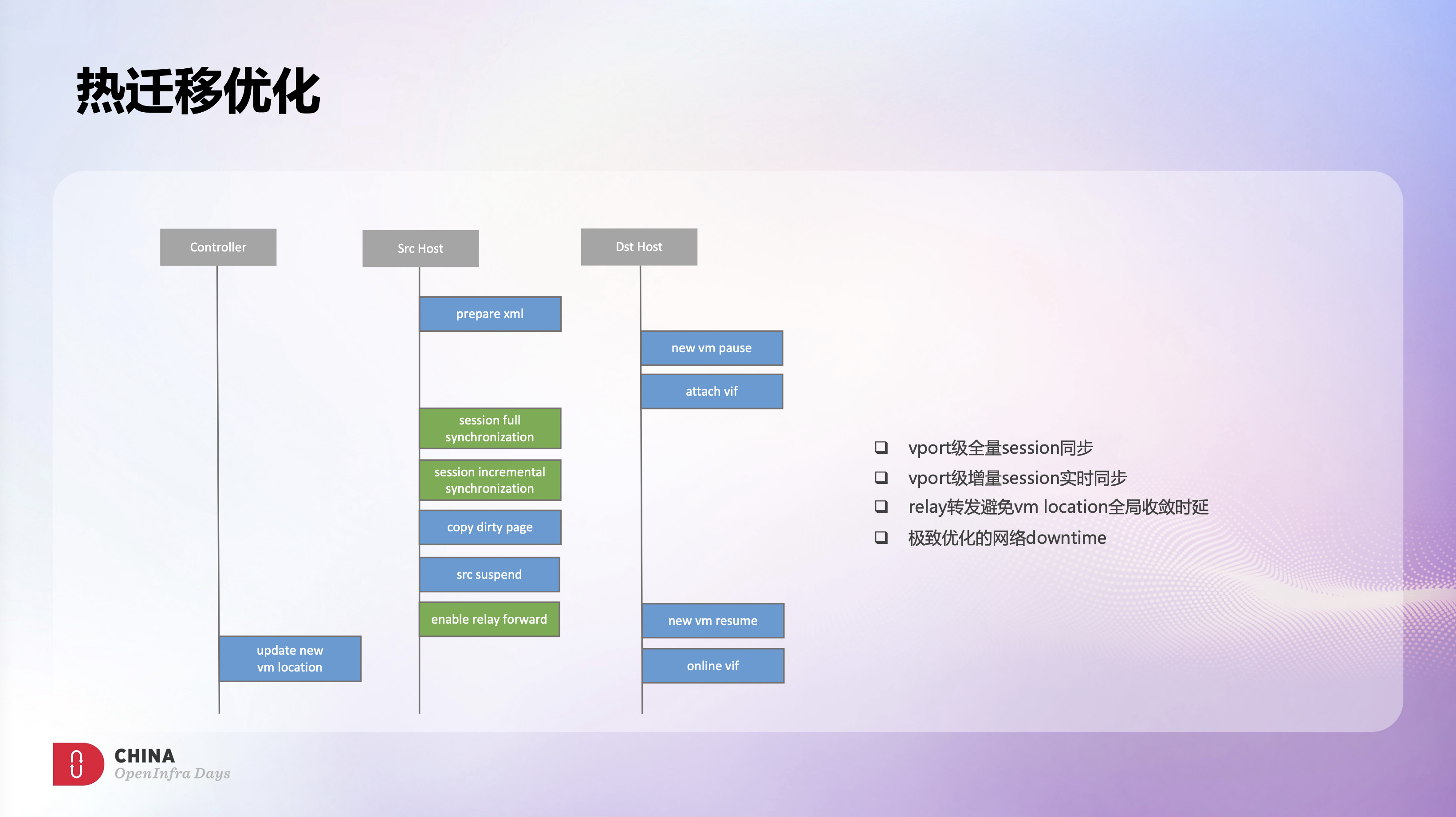
另外,早期使用OVS时,我们发现一些混部场景下OVS节点会有大量持续的imiss丢包,之前认为可能是OVS转发性能不够,来不及处理导致的,希望自研BVS可以解决这个问题。
切到BVS架构后,对应的imiss丢包虽然降低了一个数量级,但依然还有不少的imiss丢包。另外我们发现imiss丢包数和BVS PMD利用率正好成反比,PMD利用率高时基本没有imiss,而imiss峰值时PMD利用率只有50%左右,这和常见的imiss丢包是因为PMD打满导致的不太吻合。
所以我们怀疑这个可能和业务流量模型有关,结合业务场景了解到,离线业务每天凌晨开始会上量,3-4点是离线业务峰值,而离线业务特征就是大象流和微突发,这和我们看到的imiss表现也是一致的。
针对这类微突发场景,我们做了大量的尝试和优化,这里罗列了几个比较有效的优化点。首先是提升BVS自身的转发性能,除了快路径外,慢路径性能也至关重重,在大量新建业务场景下,慢路径过慢也会很大程度影响整机性能。另外调大网卡RXQ buffer可以有效提升扛突发能力,但测试发现调大RXQ buffer会导致整机吞吐下降,分析下来主要是因为RXQ buffer增大的同时会让cache miss的概率变大,最终影响了吞吐。所以我们做了些针对性的cache优化,并将RXQ buffer从4K调到了8K,imiss大概下降了30%,同时吞吐下降也控制在5%以内,这个也算是imiss和吞吐间平衡的一种选择。此外调大网卡RXQ队列数,增大网卡polling权重可以显著降低imiss丢包,将RXQ队列从4调到16,imiss大概下降了60%。所以我们也在BVS中增加了基于负载的自适应权重调度功能,来自动应对这类微突发场景,避免imiss丢包。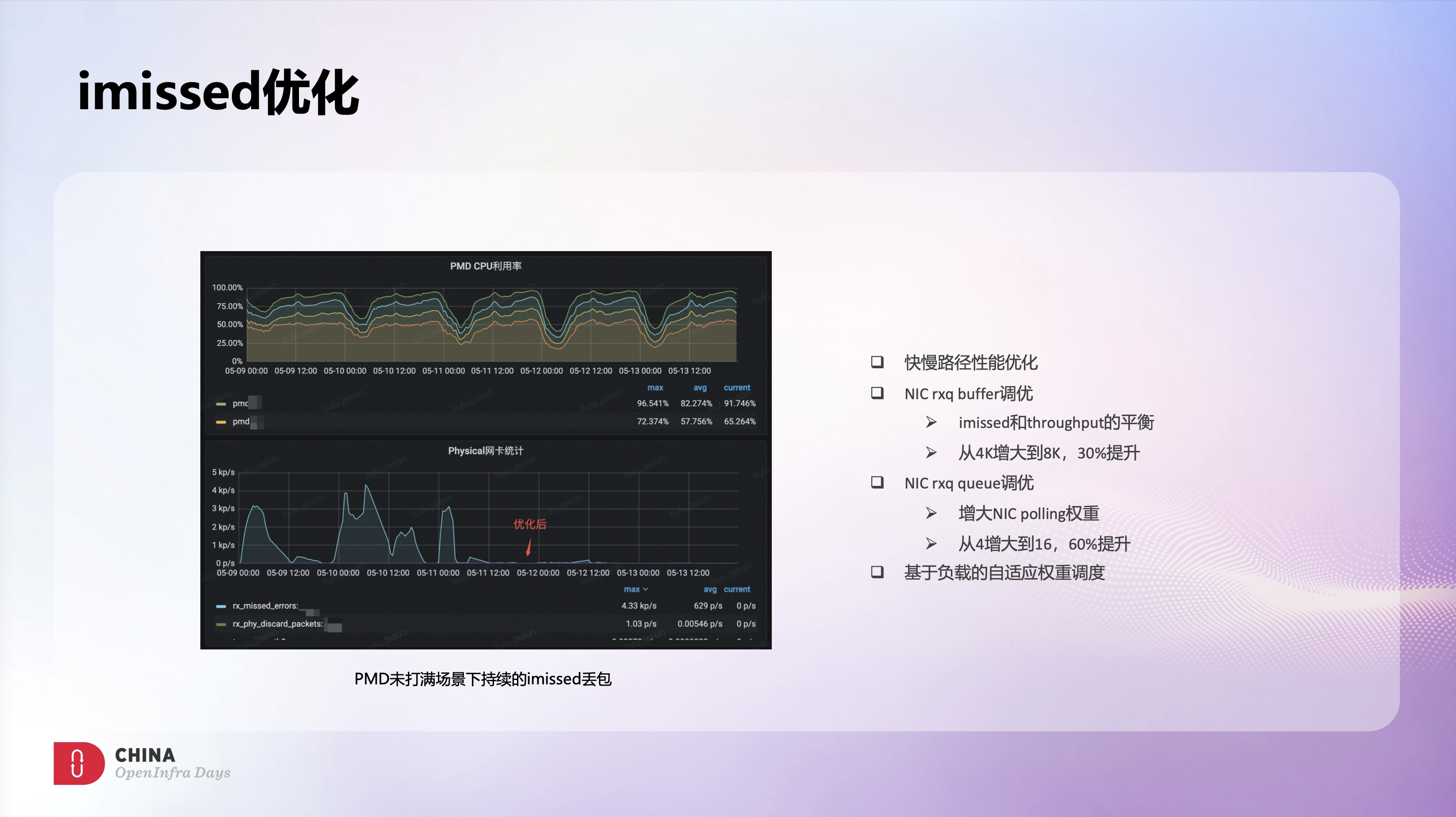
从这个监控图上可以看到整体的优化效果是非常明显的,在业务量保持不变的情况下,优化后基本上就没有太多imiss丢包了,很好的保障了业务的需求。
除了刚才提到的微突发,有些业务场景下我们也遇到了持续的多打一导致的incast。incast一直是网络领域的热点问题,VPC的多租户因素会让incast问题变的更加复杂。
基于字节内部超大规模RDMA集群的实践经验,以及自研RDMA流控算法上的积累,我们做了部分尝试,将RDMA拥塞控制的理念和算法应用到了VPC场景,希望可以缓解VPC场景下的incast问题。
VPC场景下,BVS的角色类似RDMA场景下的物理网卡,可以识别到拥塞,并进行拥塞控制。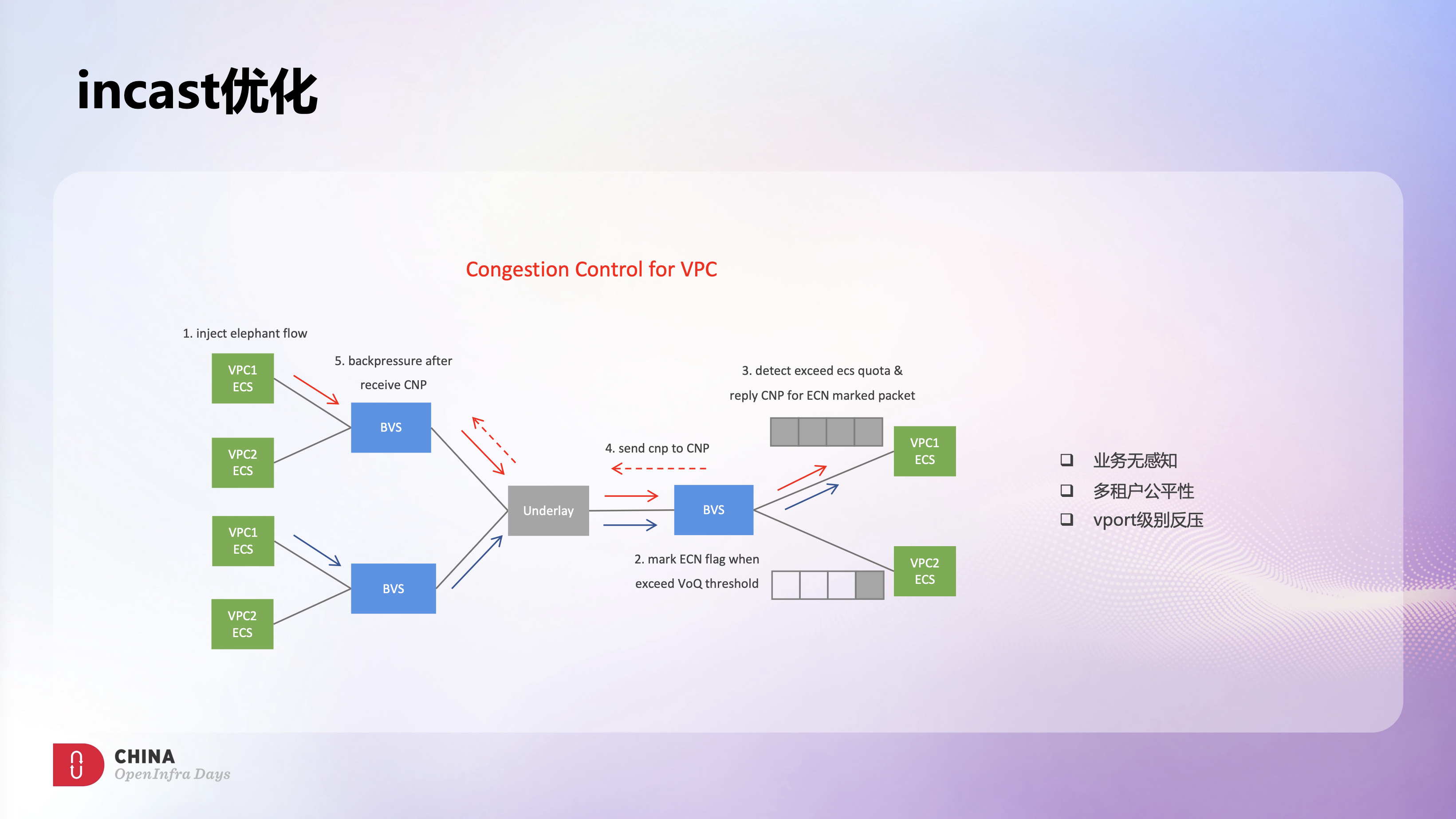
左图介绍了VPC拥塞控制的主要流程。我们在BVS ingress方向使用了网卡Virtual Output Queue的能力,当VoQ队列深度超过阈值后会将报文随机打上ECN来标记拥塞。此外,BVS也会实时监控主机的incast状态,只有在识别到incast后才会启动流控,并只对超过限速vport上打了ECN标记的报文触发CNP流控。这样只有导致incast的ECS会被流控到,其他ECS则不受影响,从而实现了多租户间的公平性。源端BVS在收到CNP报文后会启动vport级别的反压限速,从而缓解了目的端的incast。
上述方案可以有效缓解VPC场景下的incast问题,而且对用户是透明的,所有流控操作都是在BVS上实现的。当然这个方案也有些不足,例如这里的反压限速是vport级别的,虽然多租户间不会相互影响,但同个ECS内还是会出现victim flow的问题,另外VPC场景下的流控算法也还有不少的优化空间。这些都需要后续BVS能有更灵活的处理能力和软硬件协同能力。
上面介绍的主要都是BVS软件层面的优化,下面想分享些BVS在软硬件一体化上的实践和思考。通过良好的架构设计和大量的优化,BVS软转发性能还是很不错的,但是软转发需要消耗主机CPU资源,整体上来看成本依然偏高。所以我们希望通过硬件卸载,在实现超高转发性能的同时,还能减少对主机CPU的使用来降低成本,以及通过硬件转发来更稳定的应对不同业务场景的需求,减少抖动。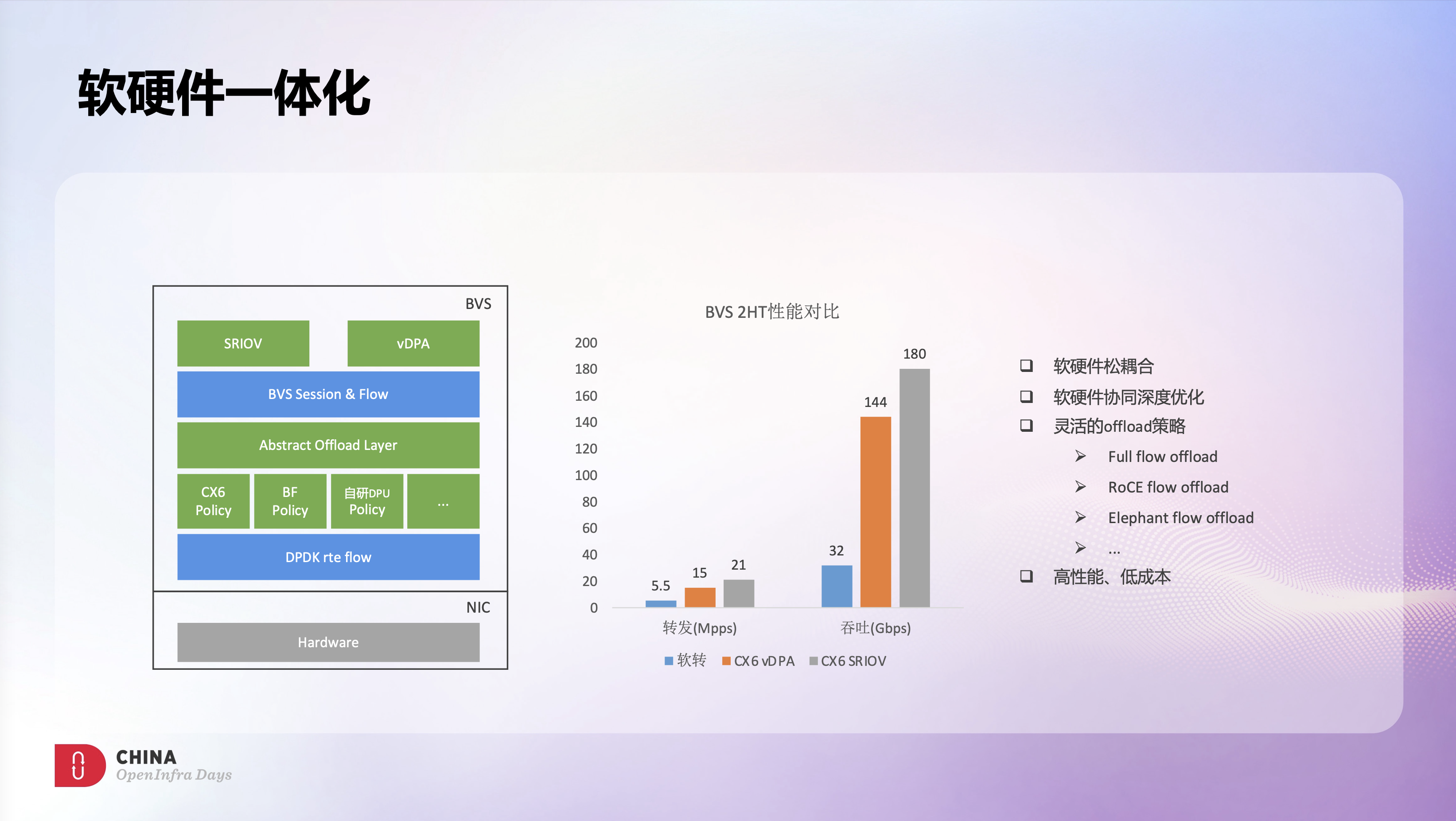
因此我们设计一套如图所示的BVS Offload框架:接口层面新增了对SRIOV和vDPA的支持;在BVS快路径层之下设计一套抽象的Offload层,用于屏蔽不同的底层硬件差异。同时针对不同硬件能力和业务场景设计了不同的Offload策略,例如自研DPU下会卸载全量规则,而CX6网卡下只会卸载大象流,HPC场景下则只会卸载RoCE流量。这样就很好的实现了软硬件的松耦合,业务层不感知底层的硬件实现,同时又能最大程度的利用好底层的硬件能力。
这里对比了2HT场景下,BVS软转发和硬件卸载的性能,可以看到Offload的性能提升还是很明显的,在大幅提升网络性能的同时,还大幅降低了网络成本。
此外,我们也做了大量软硬件协同优化,使Offload能有更好的性能,可以更好的满足业务的需求。这里举了两个优化相关的例子。
CX6 Offload默认用的是硬件单表结构,这样能有效的利用硬件资源,但同时也会遇到些难以解决的业务问题。例如VPC多租户场景下,单个VPC发生变配后需要这个VPC相关的硬件规则快速失效,但是同节点上其他VPC的硬件规则不能受到影响。在单表结构下,只能通过软件来逐条删除规则或全表批量删除,这些方法都无法满足上面的业务需求。所以我们结合了硬件多表能力和自定义tag能力,在硬件上实现了vport version语义,实现了一种基于多表结构的批量失效机制。
这里有一个例子,Egress方向,table0会基于vport id打上表示vport version的tag,然后table1中基于tag+flow key做转发,这样vport变配后只要修改table 0中这一条vport version规则,这个vport相关的所有规则就会立刻批量失效,同时不会影响同节点上其他vport的规则。Ingress方向,table0匹配flow key后打上由vport version + vport id + action id组成的tag,然后在table1中基于tag做转发,这样vport变配后只要修改table1 tag中的vport version值,就能实现类似Egress的效果。通过在硬件多表中加入类似的辅助规则,在不占用大量硬件表项的前提下,能很好的解决多租户场景下变配的隔离问题。
另外,在硬件表项老化实现上,BVS也充分利用了硬件能力,将flow老化功能卸载到了硬件实现,硬件识别到flow老化后会批量通知BVS老化事件。相比常规的轮询机制,这种事件驱动机制会更加高效,也更节约软硬件的资源开源。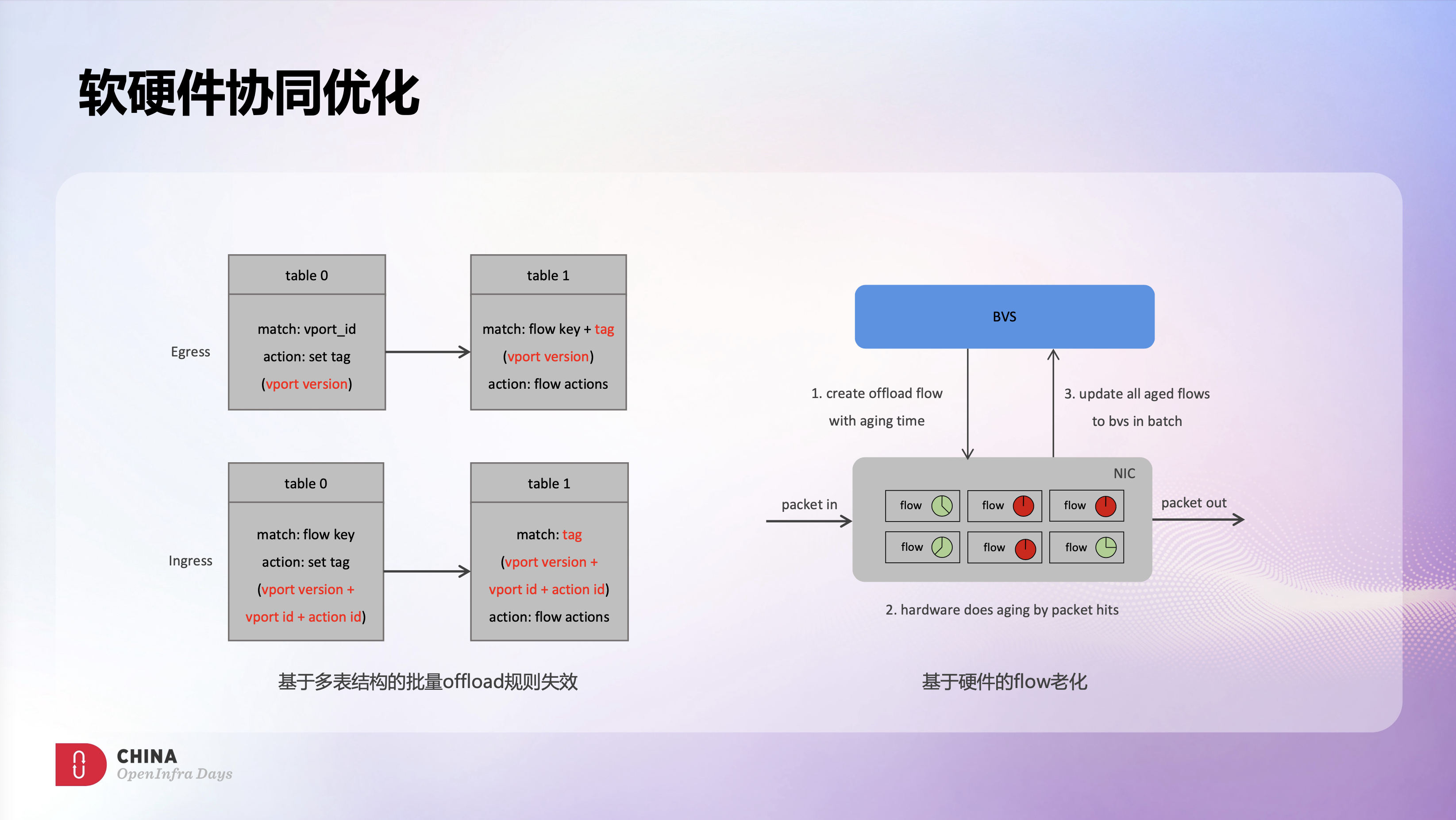
在BVS支持SRIOV Offload后,结合RDMA流控,在VPC网络上跑RDMA业务就变成了可能,这也是很多HPC业务上云的一个强烈诉求。我们和Mellanox深度合作,做了很多在VPC上跑RoCEv2流量的探索和实践。
Ingress方向,BVS使用HQoS做了两级Meter限速。这里举了个例子,例如ECS整机限速是100G,支持TCP和RDMA混跑,TCP保底是40G,RDMA保底是60G。第一级QoS会为TCP和RoCE各分配一个Meter,各自的保底流量会打上绿色标记,超过保底部分则会打上黄色标记。第二级QoS是一个color awared的Meter,在第一级QoS标记绿色的流量会默认放行,标记黄色的流量需要去争抢整机100G带宽,这样就具备TCP和RDMA混跑的基础能力。同时第二级Meter上命中黄色标记的流量会被随机打上ECN来标识拥塞,VF硬件收到带有ECN标记的报文后会主动发送CNP反压,从而触发拥塞控制。
Egress方向,BVS则使用ETS机制保障了TCP和RoCE流量在发端的公平性。
整体测下来,这个方案的流控效果还是很不错的,整体性能都是符合预期的。VPC RoCE目前还是一个很新的技术,涉及到的软硬件技术点也很多,接下来我们也会和厂商一起持续优化和改进。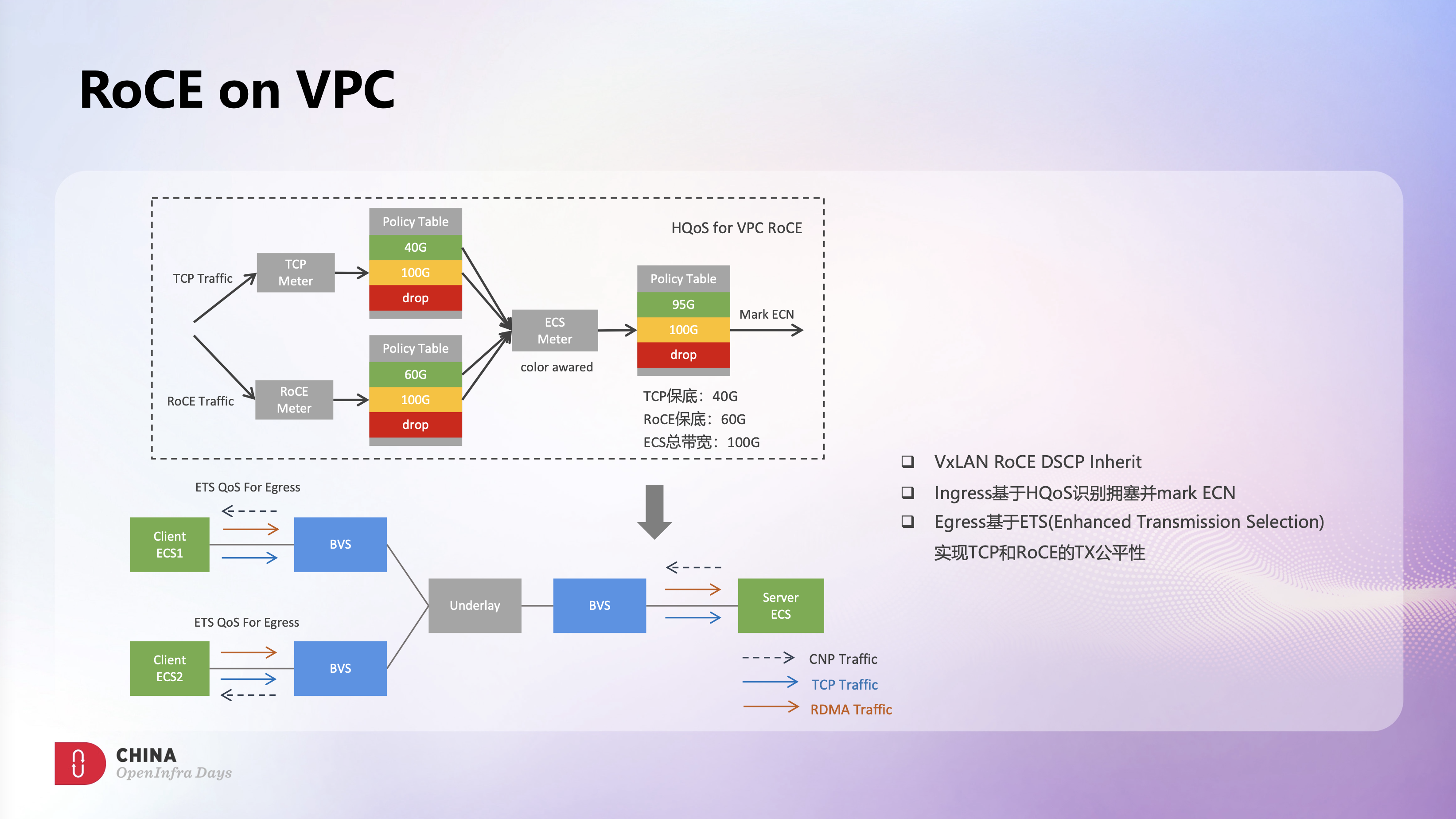
这里是VPC RoCE和Underlay RoCE的一些性能对比。吞吐方面,VPC RoCE性能还是很不错的,4K MTU场景下,VPC RoCE性能基本和Underlay持平。时延方面,VPC RoCE的时延会稍微大些,但整体还是不错的。时延这块我们也做了些分析,主要是VPC逻辑引入了更多硬件处理流程,导致了更多的时延开销,这块我们也在和厂商一起做持续优化。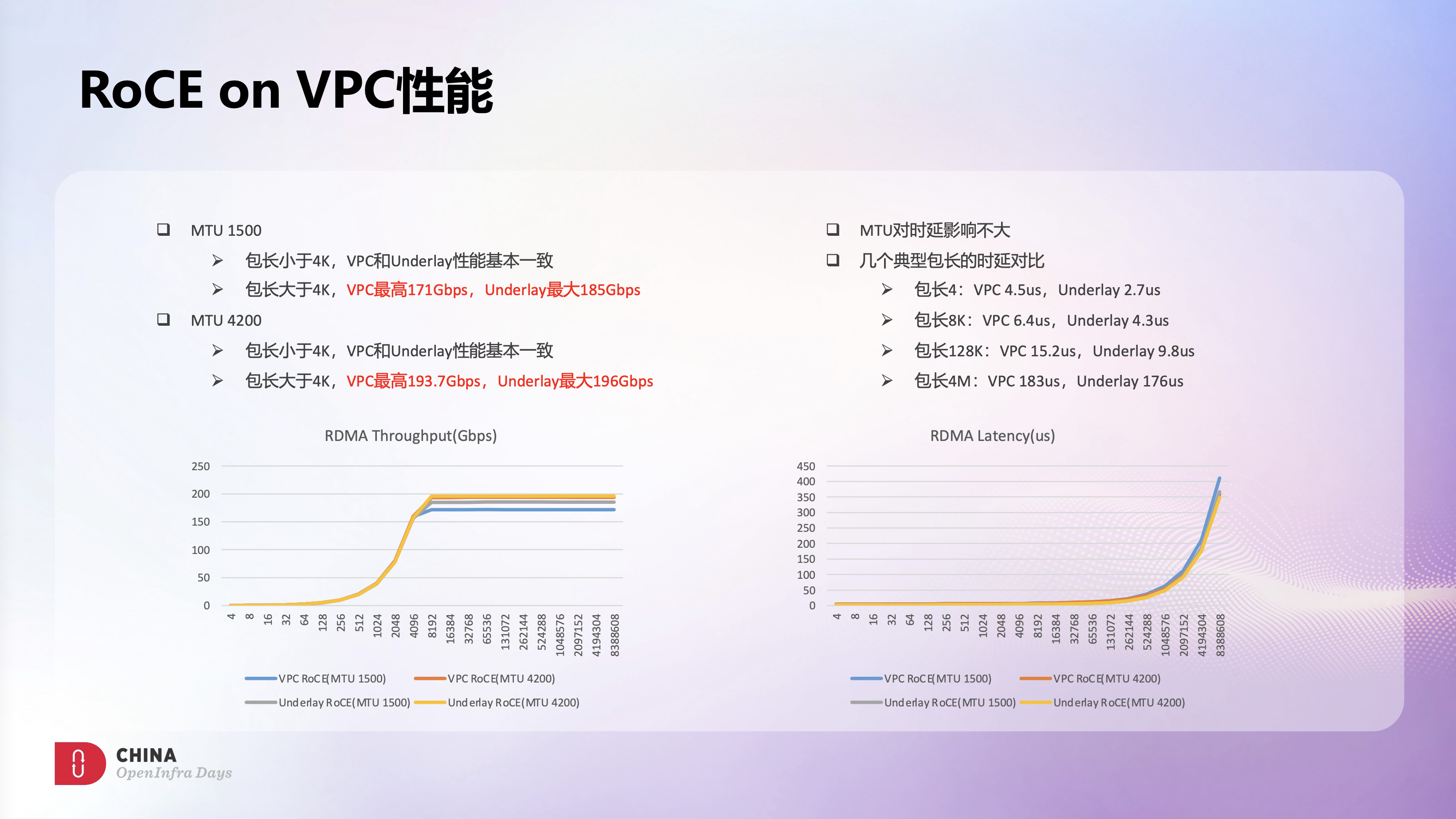
前面也提到过运维复杂度也是OVS的一个痛点,OVS因为过于通用,排查问题时需要结合多张流表规则进行分析,排查路径和排查效率都非常低。
BVS在架构设计上就是业务驱动的,有很好的运维能力和可视化能力。BVS也包含了丰富的指标信息和状态信息,所有丢包点或异常点都有明确的指标来体现,对日常运维会非常的友好。在这个监控图上可以很明确的看到ECS的限速丢包信息和安全组丢包信息,以及TCP的重传信息,这样直接的可视化能力会让问题排查变的非常简单,也更一目了然。
将BVS的指标信息和智能运维平台的诊断能力结合到一起,可以很好的实现高效运维和智能运维。这里有个自动化诊断的例子,诊断会自动化直接将所有可能的异常信息呈现出来,无论是定位速度还是运维效率都有极大的提升,很好的解决了之前OVS上遇到的痛点。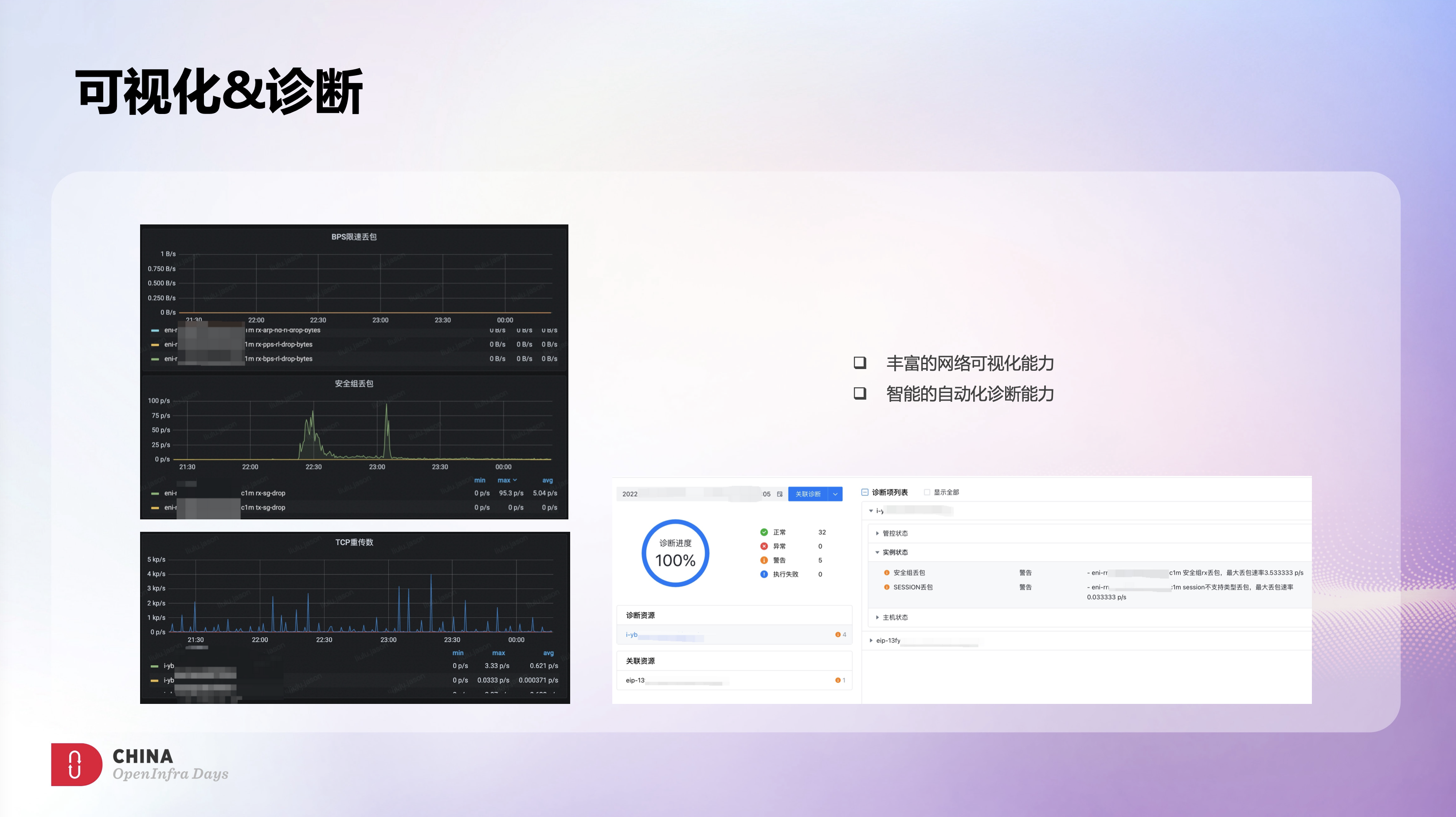
目前BVS已经在火山引擎大规模应用,ECS场景、VCI弹性容器场景、EBM裸金属场景都是采用了BVS来实现VPC能力,采用统一的技术栈,具备统一的产品能力和产品体验。
另外,基于灵活的架构设计,BVS可以针对不同的业务场景提供不同的策略,最大程度满足业务需求,同时也提升业务的竞争力。例如ECS场景需要灵活性和热迁移能力,BVS可以提供Vhost或vDPA策略;VCI场景下容器是无状态的,不需要热迁移能力,BVS则可以提供SRIOV Offload高性能方案;HPC场景需要有RDMA能力,BVS则可以提供RoCE on VPC的产品能力。
综合来看,BVS很好的解决了之前OVS上遇到的问题和挑战,在高性能、低成本、可运维方面都很好的实现了目标。通过软硬件一体化的深度结合,也能持续构建差异化的竞争力。
后续,BVS会持续演进和优化,持续为火山引擎提供更灵活、更高性能的网络产品能力。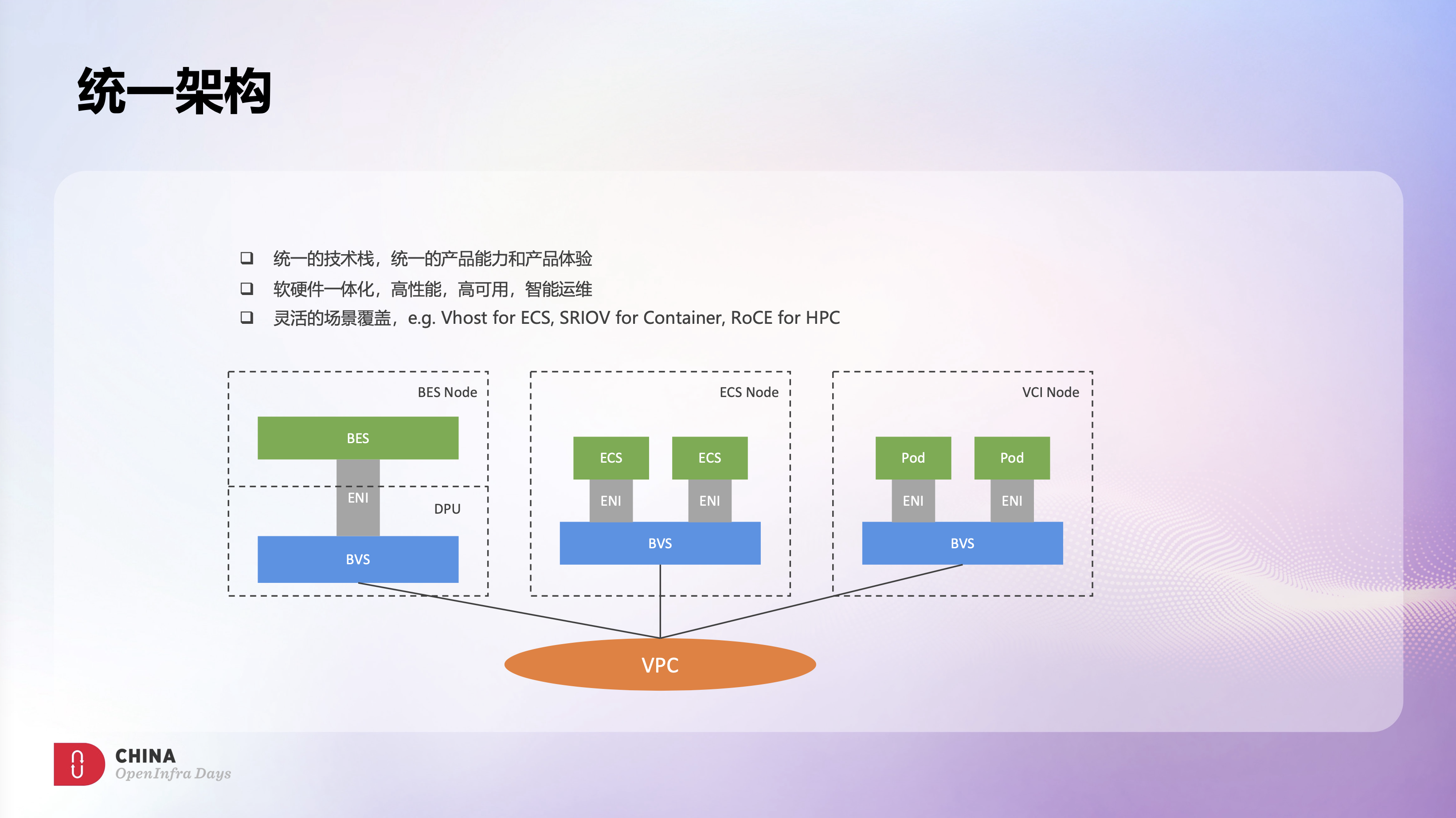
新一代火山引擎云服务器全线搭载自研vSwitch,在网络性能方面,网络传输延时可降低一半,全面提升至100G*2物理网络,最大网络带宽提升220%,单实例网络转发能力提升180%,最高可达2500万PPS,轻松应对高性能网络收发包场景,单实例支持会话数提升350%,最高可达1600万。
火山引擎云服务器具备丰富的实例类型,支持企业级应用、网站和应用服务器、数据库及缓存服务器等多样化应用场景,为用户提供稳定可靠,弹性灵活的高性价比云上算力体验。