近日,智源研究院旗下的 FlagEval 大模型评测平台发布最新评测榜单。榜单显示,在闭源大模型的“客观评测”中,豆包大模型(Doubao-Pro-4k)以综合评分75.96分排名第二,仅次于 GPT-4,是得分最高的国产大模型。在“主观评测”中,豆包大模型同样排名第二。
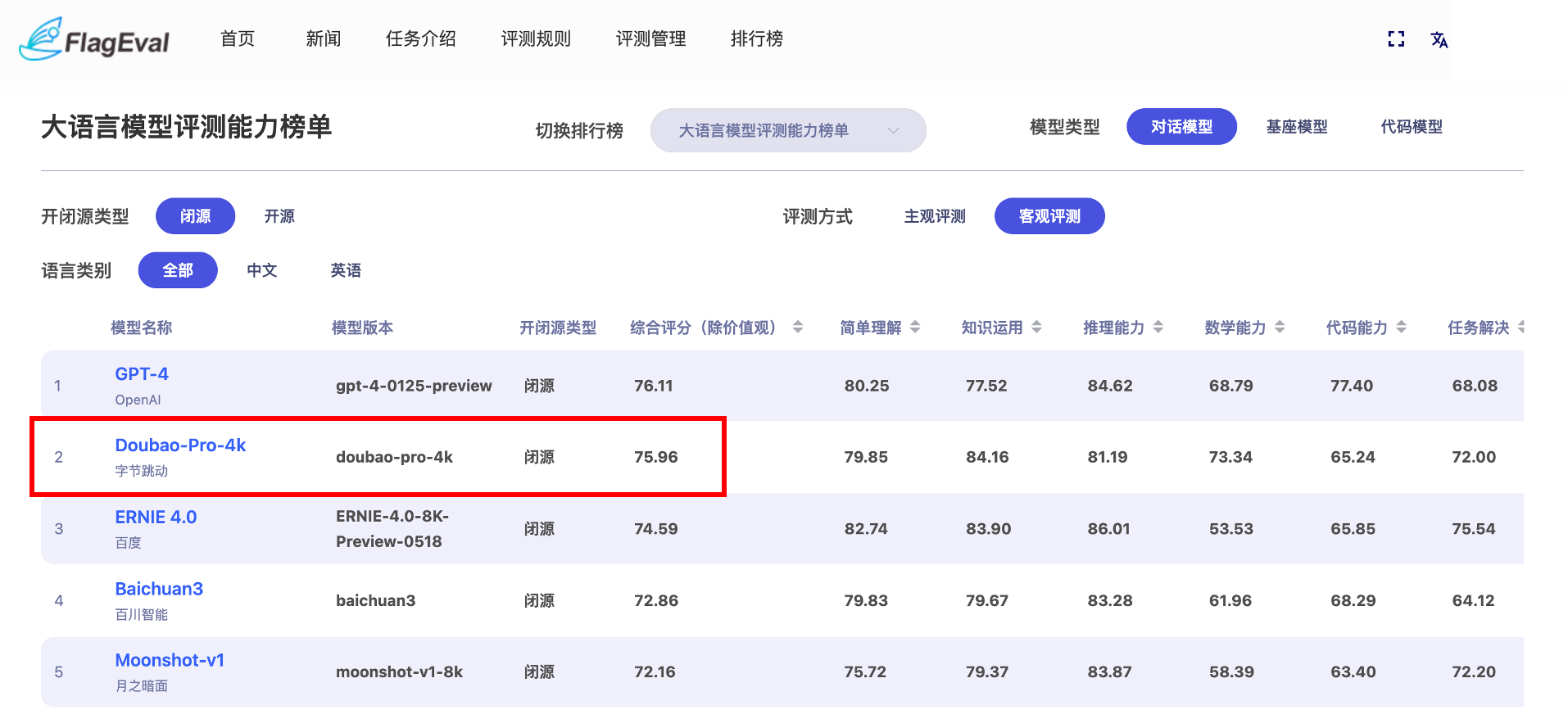
FlagEval 大模型评测能力榜单(客观评测)
FlagEval 模型评测平台由智源研究院与多个高校团队共建,以人类认知能力的发展阶梯为基准,对齐大模型所能达到的认知水平。FlagEval 构建了大量原创的非公开评测集,确保评测质量和公正性。自2023年6月上线以来,FlagEval 已完成了1,000多次覆盖全球大模型的评测。
评测成绩显示,豆包大模型(Doubao-Pro-4k)的数学能力、知识运用、任务解决等多项能力在客观评测和主观评测中都有着出色表现。其中,知识运用和数学能力得分排名客观评测第一、主观评测前三,任务解决测试得分在主客观评测中均排名前三。
豆包大模型由字节跳动自主研发,通过火山引擎正式对外提供服务。今年5月15日,火山引擎正式发布了包含豆包通用模型pro、豆包通用模型lite、豆包·角色扮演模型、豆包·语音合成模型、豆包·声音复刻模型、豆包·语音识别模型、豆包·文生图模型、豆包·Function Call模型、豆包·向量化模型等9款大模型在内的豆包大模型家族,企业可以根据自身业务场景需求,灵活选择并快速落地。
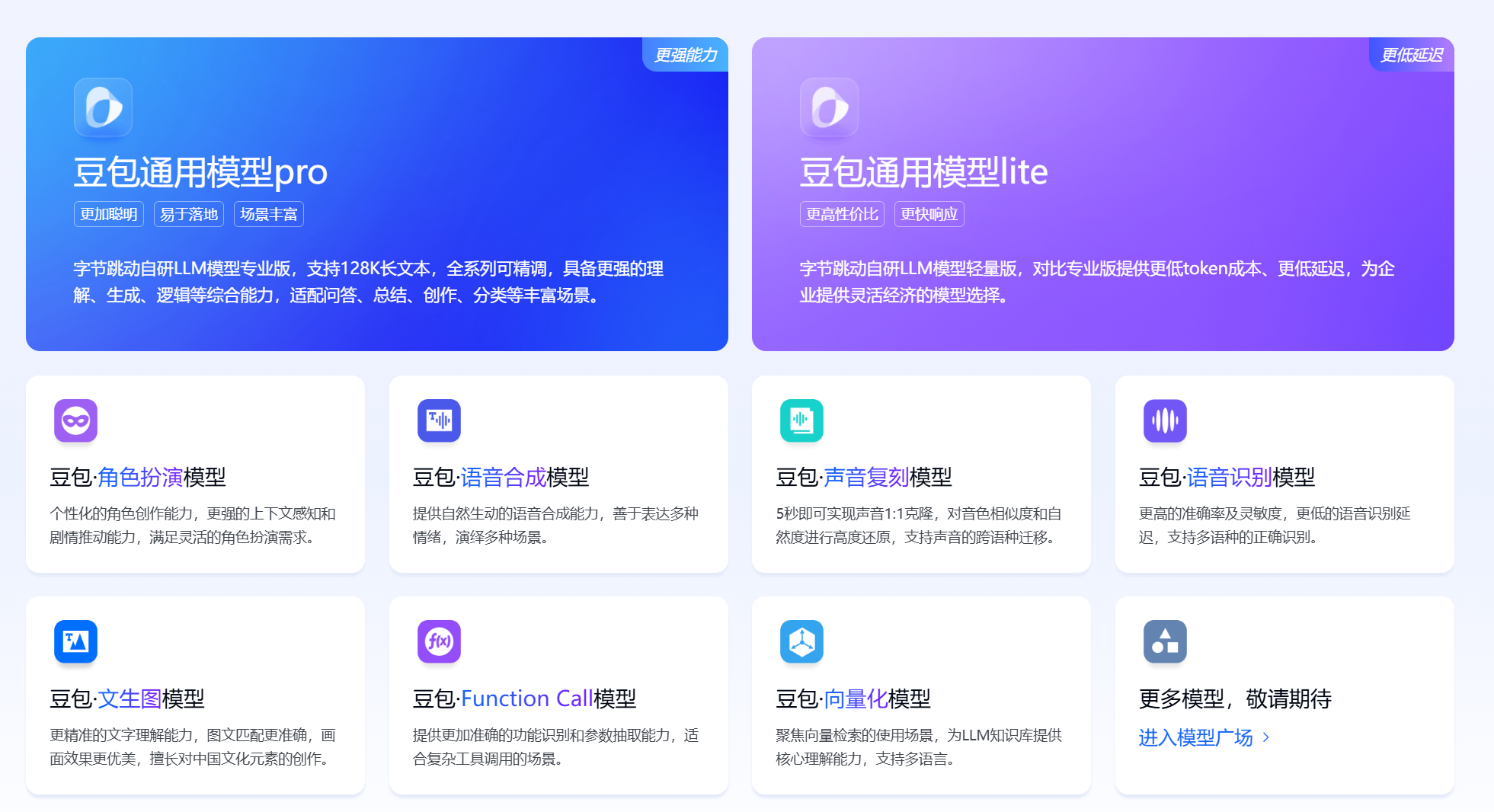
豆包大模型家族
火山引擎希望以豆包大模型更强模型、更低价格、更易落地的优势特点,帮助企业轻松构建高质量 AI 应用,在带来创新业务体验的同时,驱动业务增长。
- 更强模型:大使用量才能打磨出更好模型。豆包大模型目前已经在字节跳动内部50多个业务、多场景应用中落地,经过千亿级日 tokens 的持续打磨,模型能力和推理效果得到市场的广泛认可。
- 更低价格:为了让每一家企业都能用得起大模型,火山引擎大幅度降低大模型应用推理成本。例如本次登榜的豆包通用模型pro,其 32k 版模型推理输入价格仅为0.0008元/千 tokens。
- 更易落地:火山引擎去年发布了一站式大模型服务平台火山方舟,通过模型即服务的理念,帮助企业在高效、安全的环境里应用各类模型。近期,火山引擎对方舟平台进行了全面升级,升级后的火山方舟2.0将大幅提升模型效果、核心插件、系统性能以及平台体验,帮助企业推进大模型的价值创造。
目前,豆包大模型已在金融、汽车、智能终端、电商零售、教育科研等多个行业实践落地。未来,火山引擎将持续探索大模型在千行百业里的实践应用,继续沉淀字节跳动内部和外部客户的实践经验,通过豆包大模型、火山方舟的全栈 AI 服务,帮助企业 AI 转型落地,释放增长潜能,实现商业价值。