在刚刚结束的2022火山引擎FORCE原动力大会上,火山引擎发布了全新的机器学习平台和推荐平台的多云部署解决方案,其能够应用于科研开发、运营优化等场景中,为更多用户提供全面且领先的数智化系统服务。
火山引擎机器学习系统负责人项亮在解释统一、开放的AI基建时,表示企业希望能够赋能算法工程师,让每一个算法工程师的想法可以以最少的工程代价来实现。如果AI基建是统一、开放的,就可以在一个公平的基建上对比不同算法工程师的不同算法效果。因此,火山引擎把字节跳动的开放AI基建带给合作伙伴和客户,并正式发布机器学习平台和推荐平台的多云部署解决方案。
OPPO数智工程系统总裁刘海峰在演讲中谈到,OPPO和火山引擎两个团队紧密合作,搭建了推荐系统的混合云的服务。双方以用户体验和商业生态长期可持续的发展为目标,并且在全球范围内建设了在技术与商业两个方面都很领先的推荐算法混合云产品,成功的尝试值得业界很多同行来借鉴和参考。
NVIDIA 中国区工程和解决方案总经理赖俊杰表示,加速计算、数据中心大规模扩展和人工智能的结合正在推动科学计算和工业计算的高速发展。火山引擎和 NVIDIA 也已开展了许多合作,并在推荐系统、推理引擎、自动驾驶等多个领域都取得成果;双方还针对初创企业打造 “火山引擎 × NVIDIA 初创加速计划”,赋能更多合作伙伴。
本文内容根据三位嘉宾演讲实录整理。
火山引擎项亮:开放AI基建,让AI触手可得
大家好,欢迎大家来参加火山引擎原动力大会。字节跳动有着非常广泛的业务,比如有抖音、今日头条、西瓜视频以及直播、电商等。这些业务对AI有着非常广泛的需求,比如推荐系统、广告系统、搜索引擎、智能创作、VR等。如何支持公司丰富的业务和对AI的广泛需求,如何构建一个统一开放的AI基建,就是非常有挑战的问题。 火山引擎机器学习系统负责人项亮分享AI解决方案
火山引擎机器学习系统负责人项亮分享AI解决方案
我们采用了如下方式,各个业务都有自己的AI方向的算法工程师和自己的业务平台,但是这些算法工程师和业务平台都是基于两个通用平台构建的:推荐广告的平台和通用的机器学习平台。两个通用平台又构建在一个统一的机器学习系统之上,机器学习系统主要给上层提供了分布式的推理和调度能力,构建在更底层的计算网络、存储等基础设施之上。
为什么需要构建一个统一、开放的AI基建呢?核心原因是希望能够赋能算法工程师,希望让每一个算法工程师的想法可以以最少的工程代价来实现。如果AI基建是统一、开放的,就可以在一个公平的基建上对比不同算法工程师的不同算法效果。因此,火山引擎把字节跳动的开放AI基建带给合作伙伴和客户,并正式发布机器学习平台和推荐平台的多云部署解决方案。
下面简单给大家介绍一下机器学习平台和智能推荐平台的相关内容。我们的机器学习平台是一个面向性能极致优化的产品,我主要从三个机器学习研发中常见的痛点来介绍一下机器学习平台。
第一个痛点是资源利用率,很多企业会给算法工程师购买大量的硬件,比如有CPU、GPU等,如何让这些卡的申请率、利用率价值很高,这是一个重要的问题。首先的痛点是来自于调度,传统方法是把卡分配给人,利用率很低,而且如果卡的规模不大,调度碎片会非常厉害,你会发现买了1000张卡,但高峰期不可能都用起来。火山引擎充分利用了字节跳动内外复用的能力,给客户可以提供0碎片体验,也就是说买了多少张卡最多就能用到这么多卡。
第二个痛点就是性能上的,所有的算法工程师都希望越快越好。我们主要从三个方面帮助客户,第一个是计算方面,主要提供在一些GPU算法上的手工优化和编译优化的服务;其次在通信方面,我们也开源了两个通信相关的库,帮助大家加速自己的训练程序,一个是参数同步的通信库BytePS,还有一个是超大模型的模型并行框架veGiantModel;最后是存储方面,在机器学习调研中有可能要处理很大的文件,也有可能处理很多小文件,同时算法工程师对存储灵活性要求也很高。我们主要通过两个产品来解决大家的痛点,一个是TOS对象存储系统,另一个是vePFS分布式文件系统,两个系统相互配合可以解决上面提到的用户痛点。
除此之外,开发体验也是非常重要的。在传统的开发模式里面,特别是和GPU相关的开发模式,一般都是会有一些物理开发机,然后分配给每一个算法工程师,然后算法工程师在上面开发。内部实践发现,公司内部利用率最低的卡就是用来做开发机的卡,常年利用率非常低。因为开发机卡和大的调度卡不是同一个池子,利用率很难提升。
算法工程师肯定对复现别人的代码,或者把自己做的很好的项目让别人复现也是有很大的需求。但是复现一个项目是很难的,光有代码不行,还得有环境、数据,甚至硬件得想办法提供尽量对齐和统一的环境,机器学习平台主要是在这些方面帮助开发者。首先开发机模块,可以记录每一次迭代的数据、代码和环境,环境通过容器来提供。同时开发机对齐VM体验,算法工程师可以毫无负担的关闭开发机,GPU也和正常训练的GPU是统一的池子,保证开发机不会让资源利用率变低。在开发完后,可以一键提交交付训练,到更大的GPU资源池运行。平台在实验对比、数据分析、归档方面也提供了很好的工具,方便不同算法工程师对比不同的算法效果。
下面介绍一下智能推荐平台,其主要有以上五个特点。其中第二个特点和第三个特点是和性能相关的,实时性是用户行为产生到行为进入模型训练是实时的秒级延时;大规模是借鉴字节内部超大规模推荐系统的经验,对外也可以提供非常大规模的服务能力。
端到端是指整个产品功能是齐全的,只需要给产品提供用户数据,最终就能够提供每个用户的推荐。端到端的能力有一些企业会觉得过于黑盒,可定制化程度不高,而火山引擎针对最需要定制的三个方面做了深度的开放。
第一个是特征工程,我们支持自定义的特征工程,大家可以根据自己的业务特点定义自己的用户特征;其次我们对模型开发做了深度开放,我们推出磐石训练引擎,大家可以在上面写代码,定义自己的网络结构,发起自己的训练;最后是针对来自于不同行业的客户,比如电商、广告等,我们支持不同的行业模板,大家可以根据自己行业特点定制自己的推荐系统。
最后我再呼应一下前面说的,今天正式发布了智能推荐平台和机器学习平台的多云部署解决方案,有哪些部署方式呢?首先成本最低的就是公有云部署方式;有些客户对网络隔离有需求,我们也支持VPC的部署方式;如果有一些客户希望他的物理资源上能够独享,我们也支持专属AZ的部署方式;最后如果还有一些企业对自己的数据隐私额外需求的话,我们也支持私有云的部署方式。以上四种方式都可以混合部署,实现混合云的功能。相信我们的合作伙伴和客户一定能在以上几种方式中找到适合自己的方式。
以上是我今天的全部分享。
OPPO刘海峰:引领数智化服务新时代
各位伙伴,大家好。我是来自OPPO的刘海锋,很荣幸今天能够在这里跟大家分享OPPO对于数智时代的思考,以及在过去几年OPPO与火山引擎的一些合作进展。
OPPO作为一家全球化的智能终端与科技生态型企业,我们一直致力于为用户创造智美的体验,我们的核心产品包括手机、手表、耳机、电视、Pad等一系列终端硬件产品,同时我们还持续开发和运营数十款自有的APP。截止到今年的1月份,我们全球设备的活跃用户突破5亿。
技术角度,OPPO的技术可以分为三个领域:第一,终端硬件技术,也就是对终端硬件的规划、设计、生产、制造;第二,终端软件技术,基于安卓生态的系统软件的构建;第三,大家可能了解不多,但其实对我们这家企业也非常的重要,数智技术,这个工作主要发生在云端,需要端云协同。
根植于丰富的用户场景,OPPO数智工程的团队希望通过端云协同、数据驱动和智能计算,来为我们的终端用户提供更高效、更便捷、更个性化的多端互融的体验。
OPPO的数智技术的架构分成如上几层技术堆栈,最底层是全球混合云的基础设施,因为我们有超过50%以上的用户是在海外;基础设施之上是云原生的数据湖、仓;再往上基于海量数据的端云协同的机器学习系统;之上是AI能力层,会覆盖语音语义、视觉知识,以及推荐搜索广告等等,其中推荐算法对我们的用户体验和商业增长都非常的重要;贴近用户的多终端、多场景的业务应用,主要包括软件商店、浏览器、游戏的分发,还有我们的AI产品小布等等,我们的业务应用会分为工具型、内容型和创新型。
数智技术会为海量的用户服务提供强有力的技术支撑。在计算资源与数据处理方面,以季度为单位,我们新增的照片会超过300亿;在机器学习系统层面,结合我们的终端产业属性,我们要构建端云协同的大规模的机器学习系统,来充分发挥端侧低延迟、云侧大算力的特点;在AI技术能力表现上,OPPO AI主要是在语音语义、视觉推荐方面取得了进展;值得一提的是,我们实际上会服务多个月活过亿的个性化的推荐应用:比如说锁屏,用户一滑手机就可以看到我们的内容;再者如主题商店、浏览器里的信息流、软件分发产品等等。
在过去几年里,OPPO逐步构建了安全与隐私的防护体系,为应用开发者提供从应用检测、恶意防护到工具对抗的全方位安全保障。
因为产业特性,OPPO云端技术架构有鲜明的混合多云特点,我们将混合云架构应用到各个层面。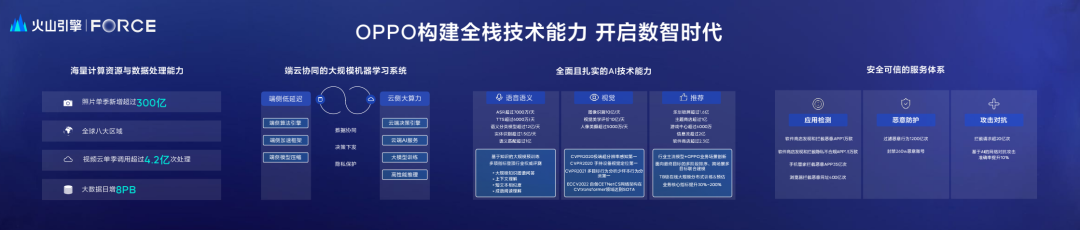
第一,是全球基础设施,我们全球混合云的基础设施分布在世界不同的地域,为不同国家的5亿用户提供就近访问的优质服务。在国内,主要依托自己的私有云的基础架构;在海外,AWS、Google是我们的合作伙伴,给不同国家用户提供就近的访问。
第二,在AI模型训练方面,内部的AI计算平台称为Green AI,也会将GPU等模型训练任务调度到内部的私有云和公有云上来分步运行,让智能计算更加的高效,也更低碳。
第三,最重要的一点,就是推荐算法服务,这是应用层面,或者业务层面的混合云的系统。前面提到,推荐算法对于OPPO的用户体验以及商业价值创造都至关重要,我们有数十个自有的APP,其中有十余款非常活跃,这几款产品都需要个性化的智能推荐体验。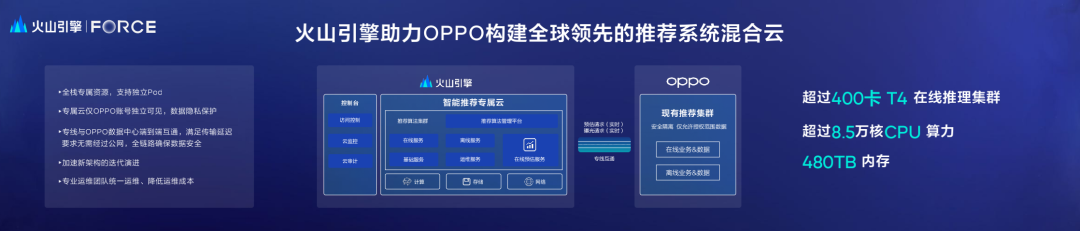
在推荐算法领域,字节跳动是全球的领先者。于是在过去几年里,我们两个团队紧密合作,搭建了推荐系统的混合云的服务。我们的推荐系统混合云有两个架构的范式:第一个范式,是双方的场景互补,比如说有一个产品有一些场景会由我们自建算法来做,有一些场景会由火山引擎的团队来提供服务。由于业务场景比较多元,一支团队很难会把所有的场景做到很深,我们可以形成合力,共同为用户提供最好的体验。第二个范式,是对一些大的业务的场景,比如说软件商店的首页,还有游戏分发的首页等等,双方同时提供算法服务,按流量分配,形成一种良性的竞合的关系,互相此消彼长、彼此促进。
随着双方合作的加深,在技术层面,火山引擎也持续对推荐算法的专属云进行技术升级,特别是对在线、离线的全链路优化,针对PS的全栈的软硬件的协同优化,可以用来提升包转发的性能等等。
在过去多年的合作里,OPPO和火山引擎都以用户体验和商业生态长期可持续的发展为目标。在过去两年里,两个团队各项的算法指标在多个业务场景里都取得了显著的提升,双方鼎力合作,在全球范围内建设了一个在技术与商业两个方面都很领先的推荐算法混合云产品,成功的尝试值得业界很多同行来借鉴和参考。
我们相信数智化的服务将为用户提供全场景、多终端、协同创新的用户体验。未来,OPPO将继续携手火山引擎,共同为用户和合作伙伴提供最好的服务,谢谢大家!
NVIDIA赖俊杰:新一代架构创新,继续推动云上普惠AI
过去十年,在计算能力的构建,和对应用程序的计算性能的提升上,发生了跨越式发展。加速计算和异构计算已经成为业界共识,围绕着 GPU 芯片,NVIDIA 建立了丰富的加速计算软件生态。数据中心因其具有强大的扩展能力,能够支撑起超大规模的计算任务,已经成为新的计算单元。人工智能的广泛应用成为最具变革性的驱动力,很多科学计算程序用神经网络进行模拟代替,进一步的简化计算、提高速度。加速计算、数据中心、大规模扩展和人工智能的结合正在推动科学计算和工业计算的高速发展,实现百万倍的性能飞跃,从而解决像气候变化、药物研发、数字孪生等以往具有计算挑战的问题。
Transformer:Transformer 结构是主流的 BERT、GPT-3 等自然语言处理模型的基础,最近也越来越多的应用于计算机视觉、蛋白质结构预测等其他不同领域。AI大模型是大势所趋,而大模型的训练任务对显存、计算和通信能力都产生了很大的挑战。所以如何针对 Transformer 模型结构的特点,结合硬件的特性,充分发挥计算系统的并行计算能力,对于加速各种大模型训练任务至关重要。Digital Twin:工业数字孪生,数字孪生技术利用现实中的数据,将物理世界在虚拟世界中复现出来,进而帮助人们优化工作流程,提升工业品在研发、测试验证、运维等全生命周期内的收益。数字孪生依赖于云计算、人工智能、3D建模、物理仿真、大数据等关键技术提供支撑,因其对速度和精度的高要求,对复杂系统的建模一直是一个巨大的挑战。Hopper:NVIDIA 作为加速计算领域的先行者,不断革新着 GPU 架构,以期能够更好地解决这些挑战和问题。比如针对深度神经网络计算任务提出的 Tensor Core,并提供对更多精度以及稀疏计算的支持。另外,也包含了能优化加速 Transformer 结构计算的 Transformer Engine。而 NVIDIA 最新发布的 GPU 架构,代号则命名为 Hopper,随着 Hopper 架构 GPU 的上市,相信会进一步推动计算领域和 AI 领域的变革。
火山引擎和 NVIDIA 长期共同合作,并且在多个领域都取得了卓有成效的成果。推荐系统方向:双方团队共同合作,确保能够利用最新架构的特性,借助于 NVIDIA 针对推荐系统 Pipeline 的定制优化,火山引擎可以帮助企业更快速的构建、部署和扩展最先进的深度学习推荐系统,成本显著降低,同时任务延迟也大大减少。AI 识别引擎:火山拍照识别功能包括了对常见的动植物、地标建筑、商品等 10 万+类事物的识别,训练任务繁重持久,对于推理速度要求也非常高。火山引擎基于 NVIDIA A100 Tensor Core GPU 计算平台提供了超大显存和强大的浮点计算能力,将千万级别的图片训练所需要的迭代训练周期从 5 天缩短至 3 天左右,极大缩短了项目开发周期。同时模型的推理服务采用了 NVIDIA TensorRT 推理引擎,助力其识别的线上服务速度提升了4-5倍,节省了大量计算资源,并且保证了服务的实时性和可用性。AI 模型:模型规模在不断增大,对于算力的需求也以指数级别快速提升。从 NVIDIA A100 Tensor Core GPU 到 H100 Tensor Core GPU,火山引擎一直与 NVIDIA 紧密合作,保证第一时间迭代更新其 GPU 实力产品,从而为企业客户提供更好地基础设施支持。汽车产业智能化:为了实现更高级别的智能驾驶,在开发模式、开发效率等方面还存在着诸多的瓶颈。轻舟智航与 NVIDIA、火山引擎三方合作,在火山引擎上推出了自动驾驶开发工具链轻舟矩阵,这套工具链以仿真为核心,可以打通从研发到测试运营的全流程,实现自动驾驶技术研发的高效迭代,大大降低算法测试成本,赋能自动驾驶行业上下游。同时,双方还针对初创企业打造 “火山引擎 × NVIDIA初创加速计划”,赋能更多合作伙伴。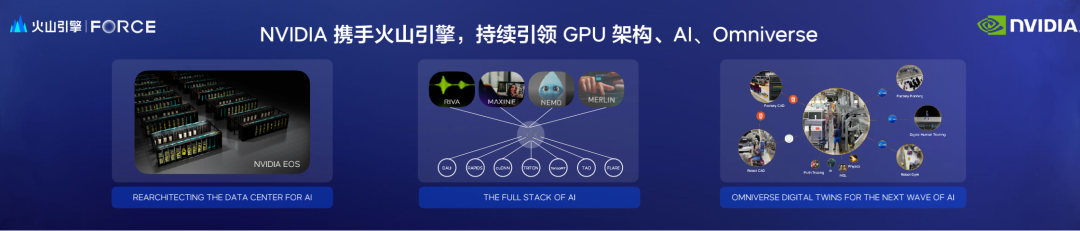
如今,人工智能技术已经在很多行业得到广泛落地,甚至深刻影响到大家的思维模式、商业路径和研发手段,计算机视觉、自然语言、推荐系统等等人工智能的应用正在推动数据中心架构设计的重大变革。为了应对日益复杂以及规模快速增长的计算任务,需要数据中心的设计者们通盘考虑任务负载,以及硬件系统的各个部分。NVIDIA 将持续在 CPU、GPU、DPU 等数据中心的关键技术中持续投入,为广大用户提供数据中心级别的高效、高可用参考方案。NVIDIA 还投入了大量软件工程师,持续开发 AI 框架软件、工具软件和应用软件,覆盖了人工智能应用的开发和部署全流程,并确保性能、可扩展性、可靠性和安全性。最后,NVIDIA 基于在 3D 渲染、光线追踪、物理仿真、人工智能、加速计算等等领域的技术积累,搭建了 Omniverse 平台,相信通过跟火山引擎的合作,可以使用户们更方便地使用数字孪生技术来推动更多产业的数字化转型。