A/B测试
A/B测试






- 文档首页
 A/B测试功能指南查看与分析实验报告实验报告概述
A/B测试功能指南查看与分析实验报告实验报告概述

DataTester为您提供实验报告功能,当实验启动后,您可在实验列表中进入实验详情和实验报告相关页面,查看报告相关数据指标和结论。本文为您介绍实验报告功能相关页面的功能概况和实验报告相关概念。
说明
您可以参考如何看懂实验报告了解进行实验报告分析的基本思路与流程,本文通过实验报告功能页面的逻辑为您介绍DataTester的实验报告分析能力。您可结合两篇文档进行学习了解,再进行自己实验报告的分析。
实验报告页面
注意
实验开启当天按实时统计实验进组人数。开启第二天之后会按T-1日天级更新,具体口径为截止当天0点的实验累计进组人数。
总览实验结论
DataTester的实验报告模块,基于假设检验理论针对实验结果对比,提供结论性的推断。实验报告页面除了展示实验的基本结论外,还包含核心指标的具体表现以及对应的天级趋势图、概率分布图和箱型图(盒须快照)。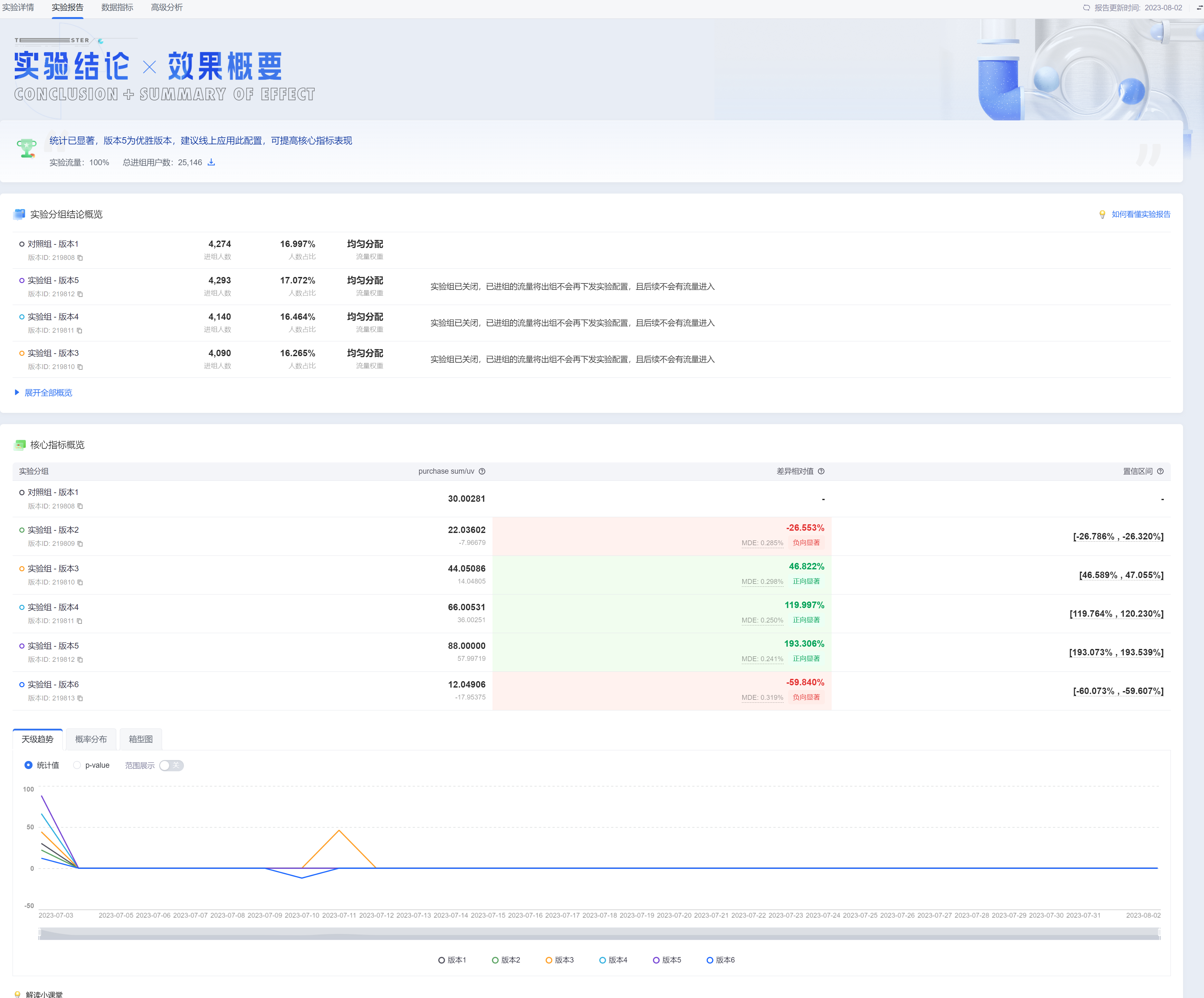
下载进组用户ID
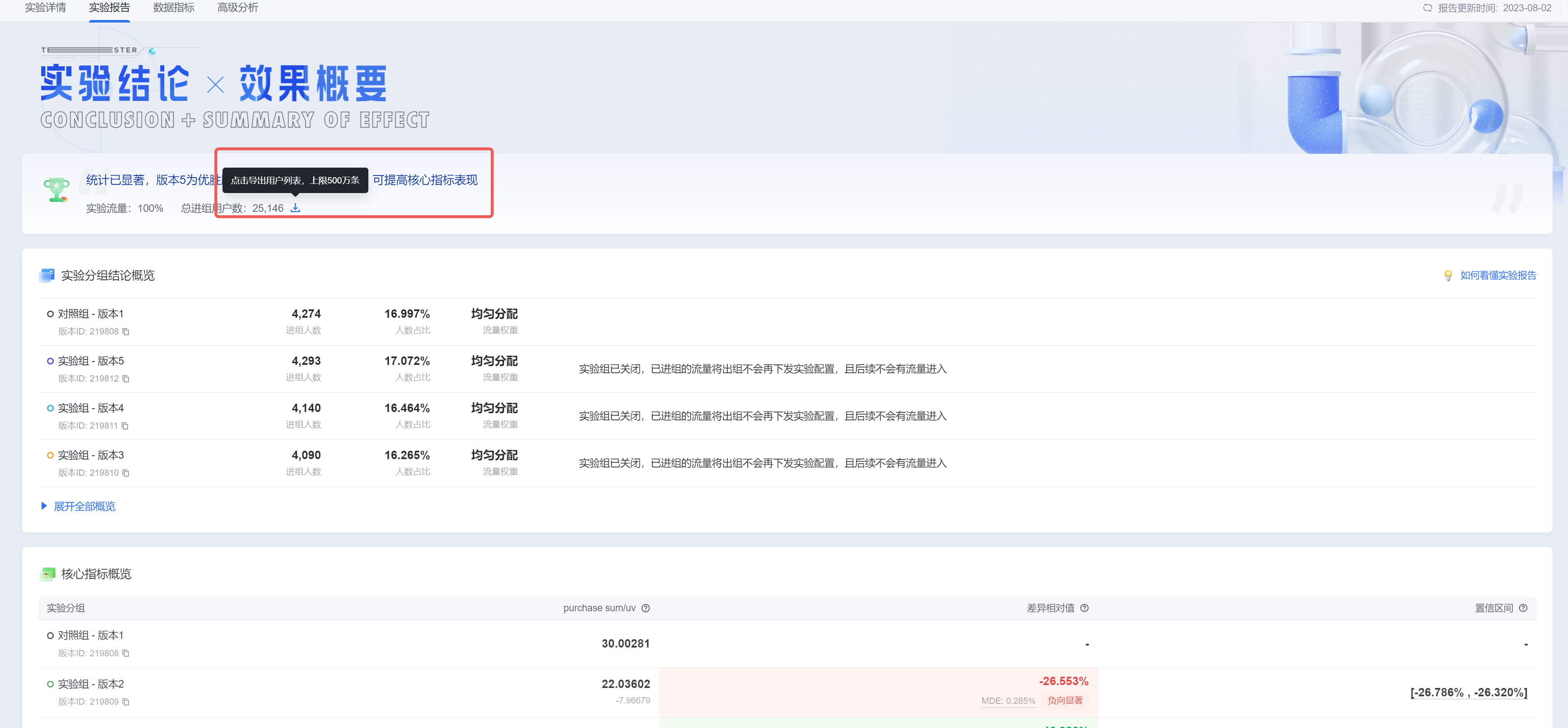
- 在实验报告页中,点击原有的进组人数可以直接下载所有进组用户ID和对应的分组信息,包含用户id、实验名称、实验分组、过滤条件(如有)信息;
说明
进组用户数的详细口径介绍请参见实验进组用户口径说明。
- 最多可以下载500万条数据
数据指标页面
您可以在数据指标页面分析查看核心指标、关注指标的数据详情。数据指标类型包含事件指标、留存指标以及漏斗指标三个大类。
- 事件指标和留存指标详情请参见:指标分析:事件指标&留存指标
- 漏斗指标详见:指标分析:漏斗指标分析
高级分析页面
同期群分析
同期群分析 :即将用户按初始行为的发生时间进行划分为群组(即 同期群)
- 对处于同期群的用户进行横向比较,从而得出相似群体随时间的变化,观察策略对用户整个生命周期的影响;
- 对不同的同期群纵向比较,可以从总体上看到,应用的表现是否越来越好了,从而验证产品改进是否取得了效果。
详见:高级分析:同期群分析
差异分析与群体对比
在做完实验后,实验结果是针对所有实验的受众人群的,可以通过数据得到相应策略有正向效果/负向效果的结论。但是一个策略对于面向全部用户的正向/负向结论,并不等同于面对细分用户也有相同的结论。这时可以使用群体对比+差异分析,得到针对某一细分人群,实验策略为正向/负向的结论。
详见:高级分析:差异分析与群体对比
实验报告指标概念汇总
术语 | 概念含义 | 对实验结果的影响 |
|---|---|---|
进组人数 | 该实验版本进组人数(即参与实验的用户数量)。进组用户数据为次日T+1数据,即1号的进组用户数据将在2号展示在报告概览中,进组用户数的详细口径说明详情请参见实验进组用户口径说明。 |
|
绝对数值 | 指的是实验组或对照组中某个关键指标的具体数值,例如转化率、点击率、平均交易额等。 | 绝对取值直接展示了在实验条件下该指标的表现水平,但并不直接反映实验处理效果的大小或方向,也不体现与另一组相比的变化情况。 |
差异绝对值/差异相对值 |
例如,如果实验组的转化率为10%,对照组为8%,那么差异绝对值为2%;差异相对值计算为(10% - 8%) / 8% = 25%。 |
|
置信区间/P-value |
总结而言,置信区间提供了一个区间范围,直观展示了估计的不确定性;而P-Value是一个单一的概率值,用于检验假设。两者都可以作为判断实验结果是否显著的依据,但置信区间提供了更多关于效应大小和方向的信息,而P-Value仅表明结果的意外程度。 | |
MDE | Minimum Detectable Effect最小可检测单位(检验灵敏度),在当前条件下能有效检出置信度的diff幅度。 说明 通常实验指标为提升/降低xx(某个业务指标值),那MDE建议以小于这个指标值来进行估算,尽量避免MDE取值较大,无法检测出真实的实验结果。更多MDE的介绍请参见基本概念中的校验灵敏度MDE部分。 | MDE对于实验结果不显著和预估实验流量方面有影响:
|
置信度和置信区间详解
概念解读
置信度
- 置信度(也称置信水平、置信系数、统计显著性),指实验组与对照组之间存在真正性能差异的概率,实验组和对照组之间衡量目标(即配置的指标)的差异不是因为随机而引起的概率。置信度使我们能够理解结果什么时候是正确的,对于大多数企业而言,一般来说,置信度高于95%都可以理解为实验结果是正确的。因此,默认情况下,「A/B测试」将置信水平参数值设置为95%。
- 在A/B实验中,由于我们只能抽取流量做小样本实验。样本流量的分布与总体流量不会完全一致,这就导致没有一个实验结果可以100%准确——即使数据涨了,也可能仅仅由抽样误差造成,跟我们采取的策略无关。在统计学中,置信度的存在就是为了描述实验结果的可信度。
在实验的过程中,我们所抽取的样本流量实际上与总体流量会存在些许的差异,这些差异就决定了我们通过实验得出的结论或多或少会存在一些“误差”。
举个例子,实验中,我通过改变落地页的颜色让购买率提升了3%,但是因为样本流量并不能完全代表总体流量,有可能“我改变颜色这一策略其实没用,购买率提升3%是抽样结果导致的”。 那么发生这种“我的策略其实没用”事件的概率有多大呢?在统计学中,我们会用“显著性水平(α)”来描述发生这一事件的概率是多少。而置信度=1-α。 在「A/B测试」平台上,根据业界标准,显著性水平α取0.05。在A/B实验中,如果发生“我的策略其实没用”这一事件的概率小于0.05,我们即称实验结论已经“统计显著/可置信”。这意味着你采取的新策略大概率(A/B实验中意味着大于95%)是有效的。相反,如果这一事件的概率大于0.05,则称实验结论“不显著/不可置信”。
「A/B测试」主要采用假设检验来计算指标的置信度,实际上,要验证的是一对相互对立的假设:原假设和备择假设。
原假设(null hypothesis):是实验者想要收集证据予以反对的假设。A/B实验中的原假设就是指“新策略没有效果”。 备择假设(alternative hypothesis):是实验者想要收集证据予以支持的假设,与原假设互斥。A/B实验中的备择假设就是指“新策略有效果”。
利用反证法来检验假设,意味着我们要利用现有的数据,通过一系列方法证明原假设是错误的(伪),并借此证明备择假设是正确的(真)。这一套方法在统计学上被称作原假设显著性检验。
置信区间
主要通过某个指标或留存的实验版本均值变化值以及置信区间来判断,在当前指标或用户留存上,实验版本是否比对照版本表现得更好。
- 如果在95%置信度下,置信区间同为正或者同为负,说明实验结果是统计显著的。
- 如果在95%置信度下,置信区间为一正一负,说明实验结果是非统计显著的。
示例
统计正向显著
如下图所示,表明实验版本样本均值对比对照版本的变化率为+46.822%。在95%置信度下,置信区间为[46.589%,47.055%],统计显著正向,说明当前的样本容量条件下已经检测出实验版本优于对照版本。
统计负向显著
如下图所示,表明实验版本样本均值对比对照版本的变化率为-26.553%。在95%置信度下,置信区间为[-26.786%,-26.320%],统计显著负向,说明当前的样本容量条件下已经检测出实验版本在核心指标上劣于对照版本。
不显著
如下图所示,表明实验版本样本均值对比对照版本的变化率为-0.941%。在95%置信度下,置信区间为[-3.552%,1.670%],置信区间一负一正,实验结果是非统计显著的。