增长分析(私有化)
增长分析(私有化)






- 文档首页
 增长分析(私有化)数据分析前规划设计埋点采集方案如何设计埋点采集方案
增长分析(私有化)数据分析前规划设计埋点采集方案如何设计埋点采集方案

埋点设计文档是面向开发的埋点需求说明书,目的是让开发理解需要在什么情况下做哪些埋点采集,以及具体需要的属性参数类型、取值,确保采集的准确性和完善性。为实现整体指标体系,数据产品落地、使用,需要对开发进行埋点方案设计,利于日后统一管理、修改、维护,保证口径统一、可追溯、易理解。
埋点设计作为数据建设的重要组成的部分,直接影响到后续的数据应用质量和数据回溯,而我们在日常中经常会碰到如下问题:
- 作为一个入职一家新公司的数据产品(分析师),面对环境中的几百个事件,或者无任何标注的属性名,茫然不知所措,不知所以然,而前任留下的文档也是似有若无,询问身边的老员工则众口不一,之前埋点的研发也离职了,干脆我就重新埋点吧……
- 作为一个运营人员,活动策划写好了,活动页面做好了,哈哈,到了大展身手的时候啦,想详细分析不同人群的数据反馈。突然发现很多属性信息没有,不足以细分,好的,什么也不用干了……
- 作为一个产品人员,新版本上线后,想详细分析新版本上线后的数据变化。内心os:还好之前提了埋点的需求,不像上面那个运营没有数据可以查。几分钟后……等等,为什么这个数据和后台业务数据很不一样……
- 作为公司的业务人员,听说公司新上了一个数据产品系统,而我前一阵子才学习了一些数据分析基础知识,内心:我也要不断进步。打开系统……几分钟后,分析模型懂,事件含义懂,属性含义懂,就是不知道这里传值的123,456……都是什么意思呀……
……
通过上面的情景再现可见,如果底层建设不好,就会造成大量的资源浪费和时间成本,以及本身数据可用价值性大大降低。只有埋点做到定义清楚可回溯、业务变化可迭代、重要需求可覆盖等,才可以避免后期返工、减少不必要的时间成本浪费,提高效率,提高数据准确度,提高数据使用率。
埋点设计可分为以下三个部分:
- 埋点项目规划
- 埋点设计方案
- 埋点数据推广应用
一个公司内不仅仅有火山引擎的增长分析的数据产品,还会有业务数据库、机器学习平台、bi系统等各种数据系统,而增长分析的数据产品需要承接什么样的需求,怎么打通各个数据产品之间的连接,是一开始最需要思考的问题。
因此初期我们可设定:
- 增长分析数据产品:主要承接行为数据和部分和行为相关的业务数据(例如支付、注册、实名认证等)的需求。
- 确立唯一用户的标识id,保证各数据系统传输id-mapping成本不高。
2.1 建立标准化流程
埋点建设的阶段我们分为两个重要的阶段。
- 初建设,0-1。
初期从0开始建设埋点体系,建议流程如下: - 长期迭代,1-N。
已经有一些埋点体系,从原来的基础上进行迭代建设,建议流程如下: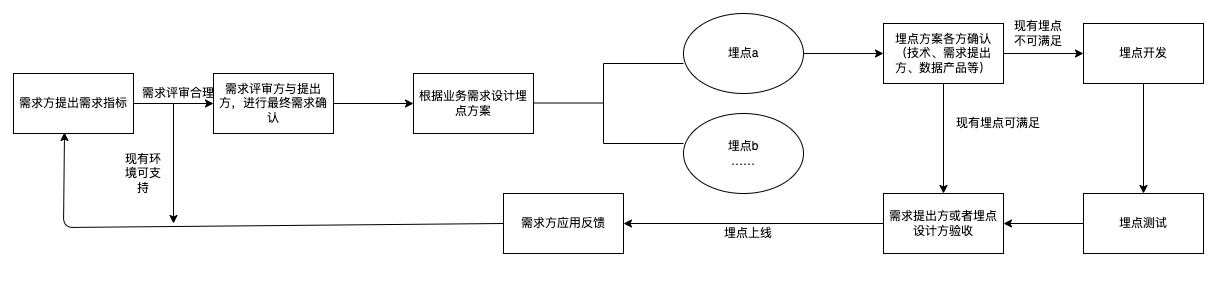
2.2 确认各角色责任人
不管是初期建设还是长期迭代,角色总共分为以下几种。
责任角色 | 责任人 | 负责内容 |
|---|---|---|
需求方 | 王某某 |
|
需求评审方 | 刘某某 |
|
埋点设计方案方 | 赵某某 |
|
埋点开发方 | 李某某 | 负责埋点的开发 |
埋点测试方 | 张某某 | 负责埋点测试 |
注意
- 埋点需求源于业务需求,为避免浪费数据资源,不能为了埋点而埋点,切莫一味追求多而全。
- 关于角色安排:
- 同一人可同时担任需求评审方与埋点设计方案方,其余角色不建议有人员重合。
- 需求方通常为产品、运营、数据分析等使用数据业务方,埋点设计与需求评审方通常为数据分析师、数据产品等数据中台建设者。
- 在埋点验收之前增加业务验收环节,是考虑部分测试人员不能准确理解业务需求,或者有遗漏,为保证埋点符合业务人员预期,如果在此环节,需求方或者埋点设计方发现不对,可在上线前及时调整。
2.3 管理小技巧
- 建议使用您的研发需求管理系统进行流程化管理。例如,为了保证各部门人员理解一致且可追溯,要制定严格的文档规范,对于需求提出的日期、背景描述、提出人、评审意见、评审人、埋点设计方案、埋点设计人、开发人员、测试人员等都要进行详细记录。
- 定期进行清理。例如对近半年没有数据接入的事件或者近半年没有被查询的事件,经业务确认后,可进行隐藏或者停用管理。
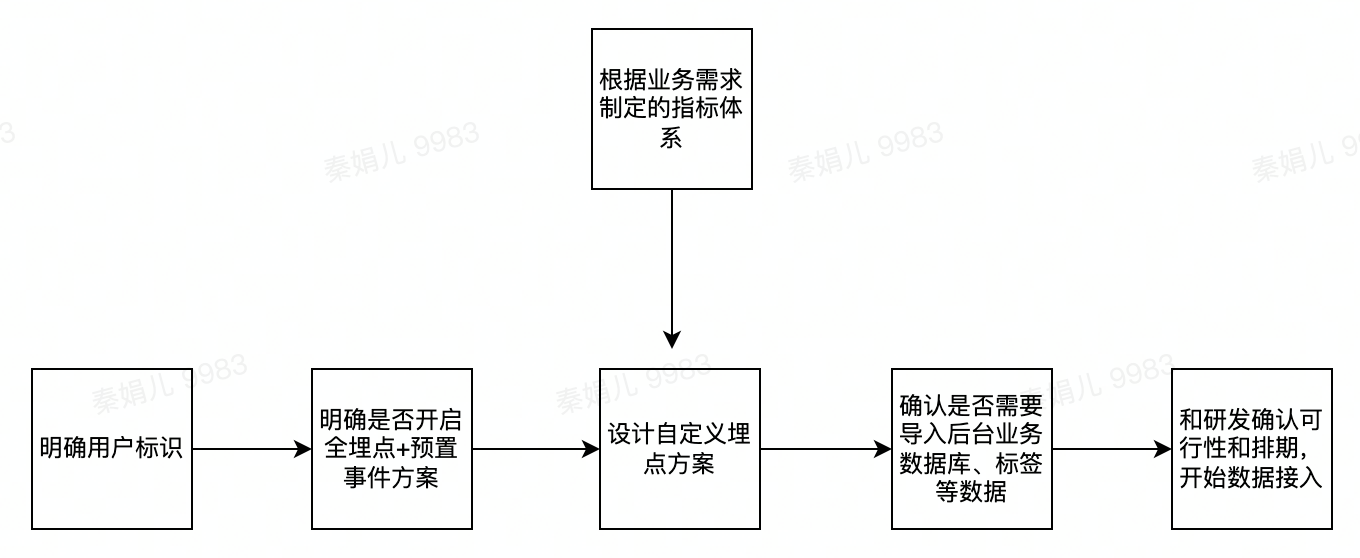
埋点设计可参考上述步骤进行设计,步骤详细注意事项将在下面进行介绍。
3.1 明确用户标识
3.1.1 用户标识底层逻辑
火山引擎增长分析使用 device_id、user_unique_id、ssid 三种 id 标识设备和用户。
详细内容可查看用户标识(uid、ssid、did)。
3.2 明确是否开启全埋点+预置事件方案
3.2.1 预置事件采集
预置事件接入基础SDK可默认自动采集,按照具体需求,选择接入对应端的SDK。
详细内容可查看文档预置用户属性/预置事件公共属性。
3.2.2 全埋点采集事件
全埋点事件接入基础SDK可选择开启或者不开启。如不明确是否开启,可咨询相关服务支持人员。
- bav2b_page 全埋点页面访问,仅开启全埋点后上报。
- bav2b_click 全埋点元素点击,仅开启全埋点后上报。
注意
全埋点具有以下优缺点,请结合实际情况谨慎开启。
- 优点:采集便利,节约投入成本。
- 缺点:消耗事件量大,且只满足一般的基础PV、UV采集指标需求,应用范围窄。
开启、不开启方式详见各个端SDK接入文档、下图为IOS SDK开启方式示例。
3.3 设计自定义埋点方案
如果想要深入分析业务,形成数据驱动,则需要在预置事件的基础上,补充更多的自定义代码埋点。自定义埋点的灵活性、自主性、应用性更高。设计埋点人员应根据业务核心诉求,形成事件设计文档,交付给研发团队进行数据接入。
自定义埋点方案示例:
序号 | 事件名称 | 事件展示名 | 属性名称 | 属性展示名 | 属性类型 | 属性值含义或示例 | 事件触发时机 | 埋点方式 | 备注 |
|---|---|---|---|---|---|---|---|---|---|
1 | regist_submit | 用户注册 | regist_type | 注册方式 | string | 手机号/邮箱... | 返回注册结果时触发 | 服务端 | |
is_success | 是否成功 | string | true/false | 返回注册结果时触发 | 服务端 | ||||
fail_reason | 失败原因 | string | 网络原因/其他原因 | 返回注册结果时触发 | 服务端 |
3.3.1 事件表-自定义埋点设计要素
序号
每个事件一个固定编号,编号唯一且不可修改,方便文档查阅、回溯,进行管理。事件名称
每个抽象的行为事件,一个中文名、一个英文名,中英文必须是一一对应关系,不可以重复,代表含义一致。 对于事件英文的命名,避免混杂不堪,需采用统一规范进行命名。建议规则有:- 可采用下划线区分-regist_submit, 或者驼峰命名区分registSubmit(由一个或多个单词连结在一起,第一个单词以小写字母开始,从第二个单词开始以后的每个单词的首字母都采用大写字母)。
- 采用动词_名词或者名词_动词进行统一。
- 如果有多条业务线,可在事件前加业务线名称的标识,例如 a_regist_submit。
- 大小写敏感,如果传了 Name,就不建议传 name。
- 自定义事件英文名不得以 $ 开头。
事件属性名称
每个事件属性,一个中文名、一个英文名,中英文必须是一一对应关系,代表含义一致。 但同一个属性可被多个事件引用,例如浏览商品详情页事件和收藏商品详情事件,可以共用属性,商品名称、商品ID等。同一属性在不同事件中字面意义相近,但实际意义有差别时,不建议复用,建议基于属性的实际含义对属性进行区分。例如:在“动画加载”的事件中,“时长”这个属性代表的意义是“加载时长”;而在“视频播放”的事件中,“时长”代表的意义是“播放时长”。在这样的情况下,不建议复用“时长”这个字段,而是拆解为两个字段分别命名。- 属性命名采取 snake 命名法,即单词全部小写,单词间用"_"分割。
- 属性命名时通常使用名词的形式。例如:product_type,product_id等。
- 自定义属性英文名不得以 $ 开头。
- 自定义属性的英文名与中文名需保持严格的一一对应。
- 大小写敏感,如果传了 Name,就不建议传 name。
事件&属性限制: - 单个应用的事件数量不超过 1000 个(不同应用之间互不影响)。
- 单个事件的属性数量推荐 300 个以内,最多不超过 500 个(不同事件之间互不影响)。
- 单个应用自定义公共属性数量不超过100。
- 事件名称和属性名称长度建议在 50 字节以内,事件属性名最长不超过 80 字节,公共属性名最长不超过64字节。
- 属性值长度建议不超过 255 字节,特殊情况如url等最大支持 2048 字节。
- 超过上述限制时,超过的事件、属性数据可能会被系统自动丢弃。
- 预置的事件和属性不可进行修改。另外服务端埋点时,无法自动采集预置公共属性,需要手动传输。
- 多端传输一定要统一好事件和属性命名,保证传输一致。
属性类型
属性值
含义
int
需要进行聚合运算(例如求和、均值)或者按区间分组的整值,典型的比如年龄、购买数量等。
float
需要进行聚合运算(例如求和、均值)或者按区间分组的小数值,典型的比如价格、时长等。
string
文本类型属性值类型,支持包含、不包含、等于等计算规则。
各类 ID (例如商品 ID)建议作为字符串类型存储。list
需在一个字段存储多个值。
例如支付订单时的“优惠券ID”这个字段,由于用户可在一笔订单内享受多个优惠,因此需以列表形式存储所有优惠券的 ID。
例如一个商品有多种标签,【‘午餐’,‘折扣’,‘圣诞节’】需用列表形式存储。
**list类型存储后,可按单个属性值进行查询,例如选择带折扣标签的商品有多少。datetime
支持日期时间格式的 string, "2020-06-19 17:51:21"
属性值含义或示例
此列意在为研发人员明确属性字段的含义,以及特殊情况的说明,便于研发人员理解与实施。属性类型
示例
可枚举属性
性别:男、女
不可枚举属性,可举例说明属性
商品品牌:A品牌、B品牌……
事件的触发时机
需说明每一个事件应在何时触发,如一个事件在多个时机均有可能会被触发,则需要整理出所有的触发时机。例如:“点击开始注册事件”的触发时机应为点击注册时,但注册通常有多个不同的入口,因此,业务人员需要明确地枚举出哪些注册入口是需要研发人员进行埋点的,如果有属性值的区分也要标注,避免遗漏。事件
属性
属性值
触发时机
点击开始注册
注册入口
首页右上
登录页去注册
首页下方- 首页右上角点击注册时触发,注册入口属性值传【首页右上】
- 登录页点击去注册时触发,注册入口属性值传【登录页去注册】
- 首页下方点击去看看时触发,注册入口属性值传【首页下方】
埋点形式
事件埋点形式支持前端、后端两种。不同时机触发,得到数据结果不一致。例如注册事件,前端提交注册时触发,无法明确注册成功还是失败。后端注册返回结果后触发,既可以明确注册结果,又可以避免前端数据丢失。一般情况下,核心业务流程事件建议后端埋点,保证数据准确性,例如:产品购买、注册成功等。在特殊情况下,也可以采用前后端协作的方式进行埋点 ,由一端将收集到的数据传给另一端后,再由数据接收端触发事件埋点。埋点形式
说明
前端(客户端)
交互、点击、浏览类前端采集为主。
后端(服务端)
核心业务例如支付、注册等,建议后端。
备注
可做排期优先级标注,以及其他特殊情况备注。
3.3.2 用户表设计要素
- 用户属性
用户属性需是描述用户较为长期状态的属性,例如人口学信息、账号信息等。 - 发生变化的用户属性
首先用户属性可进行更新,例如VIP等级、最近一次支付时间等。 需要注意的是,比如用户的 VIP 等级,用户属性只记录当前最新状态,比如VIP等级可以从level1变成level2,也可从level4变为非VIP,用户属性只记录该用户当前VIP等级的最新状态。如果想要获取用户在历史状态操作时的VIP等级需求,还需要增加事件属性VIP等级,可根据具体需求进行选择。如果有不明确的地方,可咨询相关服务支持人员。
3.3.3 公共属性
公共属性为所有事件均有的属性,例如事件发生的平台、事件所属的业务模块等。没有该业务需求时可忽略公共属性。
3.3.4 整体的设计思路
- 确立观察指标
根据前期建立的指标体系,逐个梳理。 - 抽象过程行为
抽象观察指标的行为事件,例如想要观察支付转化率?明确支付转化率的定义为应用启动-进入商品列表页-浏览商品详情页-提交订单-支付成功转化率,把每个行为抽象为一个事件。 - 补充事件属性
观察支付转化率,业务需求还远远不够,还需要观察不同商品价格的转化率,不同店铺的转化率,不同商品分类的转化率等,因此需要在能够记录这些相关信息的事件增加事件属性,方便后期做维度拆分。如图所示,浏览商品详情页可增加商品相关属性。 - 设计事件要素
将事件的触发形式、英文命名、埋点端、属性值类型、属性值示例补充完整。 - 补充用户属性
如果想看不同性别、不同注册月份的用户转化率区别,则需要增加用户属性。
3.4 确认是否需要导入后台业务数据库、标签等数据
在更多的业务场景中,有许多数据比较复杂,例如银行贷款业务数据库中,对每个用户计算的风控等级,可作为用户属性导入。
例如零售在线下交易,发生行为不在线上,或者在线教育中,对客户的线下电话促活召回,不可作为线上行为数据采集,这种存储在业务数据库的数据,也可做事件和属性的抽象,用业务数据库导入方式,并确定导入周期频率(按天、按周等),定期导入。
3.5 确认可行性和排期
设计人员应与研发逐个确认事件和属性采集的可行性与成本,对于实现成本高,需要重要性不高的需求可做取舍,并制定整体埋点优先级的排期。
相似场景是合并一个事件还是分不同的事件
事件设计
场景示例
说明
事件设计示例
设计为同一事件
例如相似场景下的按钮点击可合并,不必一个点击一个事件,需合并为一个事件。
对于全局性的事件,我们建议设计为同一事件,通过特定的属性值对特定操作进行区分,而不是针对每一个操作设计一个事件。

设计为同一事件
例如:点击banner、点击热门活动位,都是点击首页的推荐位,可通过增加属性区分。
各事件所需属性相差不大,平时分析场景多整体分析。
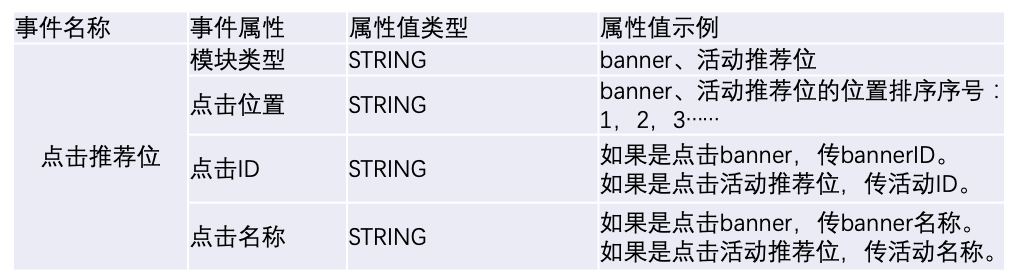
设计为不同事件
例如一个内容平台,有视频,有文章,因视频和文章所记录属性差异较大,浏览内容详情应区分为浏览视频详情和浏览文章详情
各事件所需属性相差很大,分析场景多分别分析。
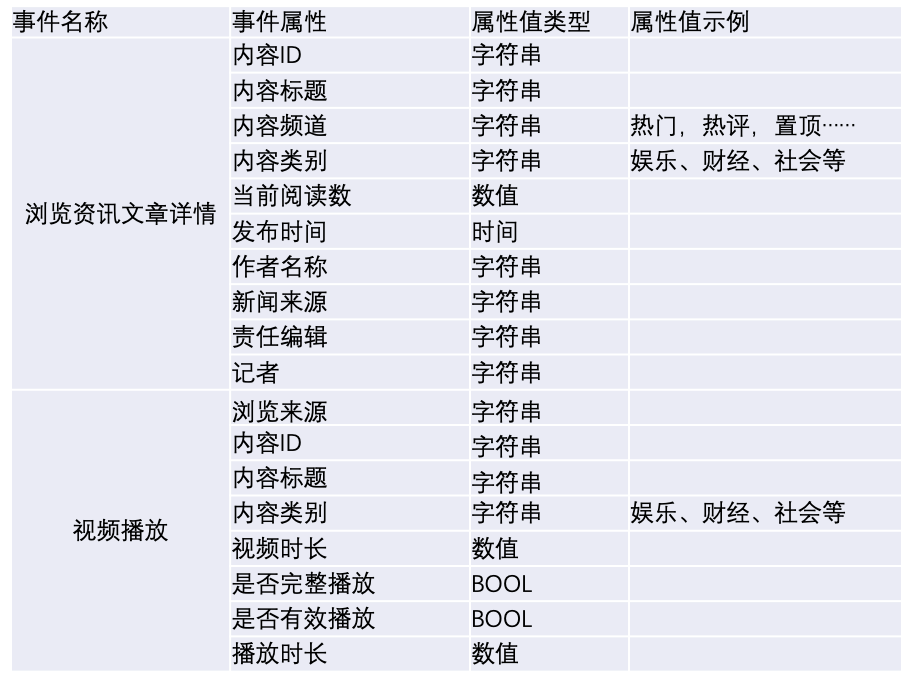
设计为不同事件
例如:收藏商品、浏览商品详情,虽属性差异不大,但是收藏和浏览业务关系不大,且通常为单独分析。
各事件所需属性相差不大,但平时分析场景单一分析,并且业务含义区别较大。
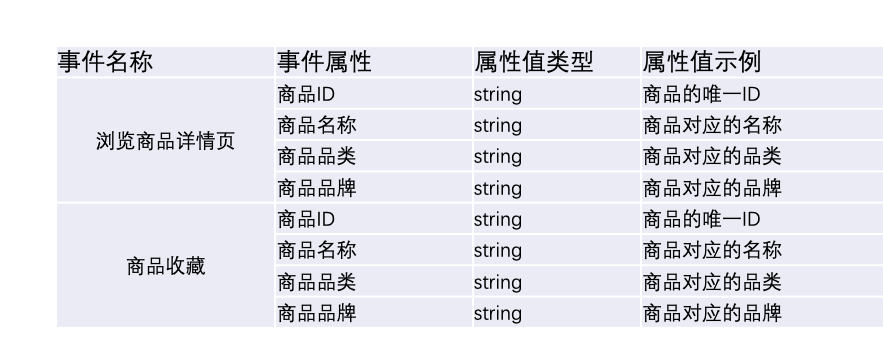
多重身份用户的设计
在在线教育用户中,有多重用户身份,例如老师、学生、家长等,要做好用户属性的区分,对不同身份用户的属性进行不同的设置。主被动事件的处理
在线上行为中,很多需要记录的埋点事件非用户主动触发,为被动触发,例如平台审核、发放优惠券、被其他人关注等,所以这种场景下不存在主动事件,主动触发行为的不是用户,用户是行为的接受者,被动受到影响。但是在分析需求比如审核通过率,需要提交审核-审核通过的主体ID为一人,此时被动事件的上报主体会影响到分析结果,具体处理方式详见官方文档被动和关系事件。曝光事件的处理
和其他事件一样,只是曝光事件的触发时机需要注意,例如某平台内容曝光事件触发时机为:- 内容露出全部,且feed流静止状态超过2s算曝光。
- 限制单一内容一次请求只会出现一次曝光(比如上下滑动屏幕,只要不刷新发生新请求,算一次曝光)。
以上仅为示例,具体的规则可根据需求和研发的实现成本灵活变动。另外,需要注意的是,曝光触发事件量巨大,一般分析CTR,或者有推荐算法数据需求时需要曝光事件,其他场景请根据需求谨慎埋点。
虚拟事件
虚拟事件是对元事件的合并和拆分,是一个特殊功能。所以在事件埋点设计时,如果虚拟事件可满足,不必增加新埋点。事件类型
示例
图示
合并事件
例如社交平台的互动行为包括:点赞、评论、喜欢、发送私信等很多行为,这时需求想分析当天发生互动行为的用户数去重。可对事件合并。
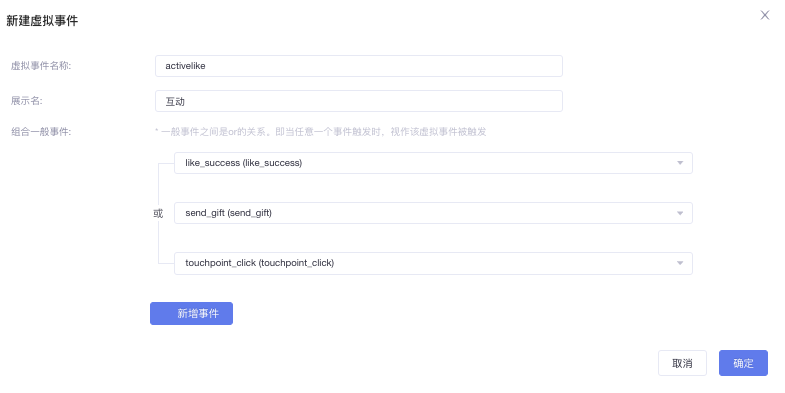
拆分事件
例如618电商活动期间,频繁看带满200减20标签的商品的加入购物车数量。不想重复性的配置指标,可设置虚拟事件。
无